線性迴歸 (linear regression) 是社會科學最仰賴的統計工具,每當你讀到報紙說,表親越多的人越快樂、開設 Burger King 越多的國家風氣越敗壞、美國人收入每增加 3% 投給共和黨的人會增加 3% 等,這些都是利用線性迴歸在預測趨勢。
我們可以很容易且聰明地,將已經發生的事情勾勒出其因果關係 (cause-and-effect relationship),這是線性思考 (linear thinking) 的心智模型 (if A then B);然而,當我們要預測未來時,通常都不管用。(Ref: Learn to Think in Systems)
simple linear regression 是度量看不見的東西或預測尚未發生的事件結果的強大工具。藉由統計學的幫忙,你就能在只看到另一個變數表現時,準確猜測某人在目標變數上可能的 scores。迴歸分析 (Regression Analysis) 是利用一組自變數 (或稱預測變數、獨立變數、predictor variable) 對某一因變數 (或稱準則變數、criterion variable) 建立關係式以便做為預測的依據,它也可以做為評估自變數對因變數的效用。迴歸的主要目的是做預測,只用一個自變數來預測應變數稱為 simple linear regression;用一個以上的自變數來預測因變數稱為 complex linear regression。
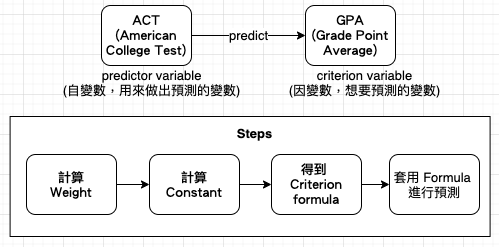
regression analysis 的適用性 (Ref: Statistics Hacks)
模型如果太簡單 (ex. 單因素模型所形成的直線),可能無法表現資料的主要型態;模型如果太複雜 (ex. 九因素模型),又會太容易受到取得資料點的影響,這就是統計學家提到的 overfit (過度配適)。在機器學習領域有個十分重要的事實,使用因素較多、較複雜的模型,未必能得到較好的預測結果,複雜型帶來的問題,反而使我們的預測變得更糟。
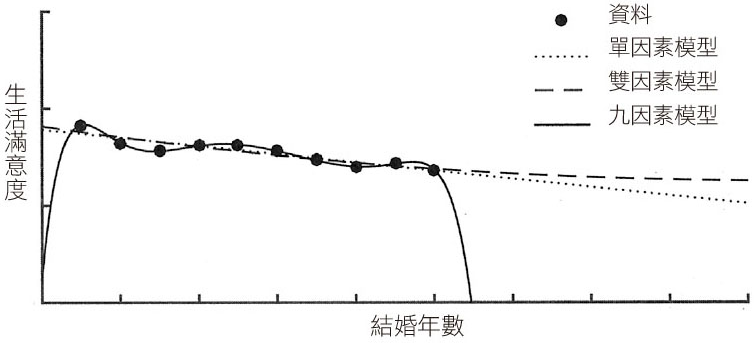
若樣本資料極具代表性,採用最複雜的模型會是個好辦法;若樣本資料有偏差,採用最複雜的模型就會容易遭受雜訊 (noise) 影響,遭遇過度配適 (overfit) 問題。overfit 就是資料的偶像崇拜,因為我們只注意到測量的資料,反而忽視真正重要的東西。
以統計學家的觀點,overfit 是對已知實際資料過度敏感的症狀 (ex. 學生很熟悉會考的方向),解決方法很直接,抑制想找出完全符合模型複雜度的念頭。在統計學和機器學習中,Lasso 演算法對因素權重施加向下的壓力,最多可使它變成 0,只有對結果有明顯影響的因素才能繼續保留在方程式中,因此,一個 overfit 的九因素模型,可簡化到只剩下少數幾個重要因素,方程式也因此變得簡單穩定,增強統計模型的預測準確性和可解釋性。

No comments:
Post a Comment