第十五章 特異功能真的存在嗎?(Don’t Confuse Me the Facts )
超感知覺/胡迪尼的挑戰/一個家庭對超自然現象的著迷
所謂的 ESP 是獨立於傳統五感 (sight, sound, touch, taste, and smell) 以外的感官知覺。大多數的科學家都同意 ESP 實際存在的證據不多,但他們可能是錯的。你或你的朋友或你養的狗可能有 ESP,而現代就是找出它們的最佳時代。
Zener Cards |
|
|

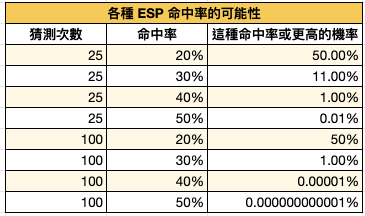
哪個比較好?人與人之間真有差異嗎?如果你想要為你的這些關於最好、最多或最少的信念找出一些真實的證據,你可以使用獨立 t 檢定 (independent t test) 來支持你的論點。例如,M&M 巧克力綠色比藍色好吃、女人永遠不會收到罰單等。t-test 源自於啤酒統計學家為了判斷啤酒製造過程中,裝滿整部升降機的穀物品質,因無法檢查所有穀物,故設法檢視隨機從較大的穀物母體抽出的一個小型樣本的方法。假設我們想驗證,女生永遠不會收到超速罰單:
罰單數 | ||||||||||||||||
Group 1 (male) | Group 2 (female) | |||||||||||||||
平均數 (mean) | 1.71 | 1.35 | ||||||||||||||
變異數 (variance) | 0.71 | 0.25 | ||||||||||||||
樣本大小 (sample size) | 15 | 15 | ||||||||||||||
計算過程 | ||||||||||||||||
t=Mean of Group 1 - Mean of Group 2Variance for Group 1Sample Size of Group 1+Variance for Group 2Sample Size of Group 2=1.71-1.350.7115+0.2515=1.42 | ||||||||||||||||
< 5% 的機率偶然發生的 t 值 | ||||||||||||||||
| ||||||||||||||||
中立的研究人員應該分析所有資料,包括正確與錯誤的預測,包括正面與負面結果。選擇性的報告也被稱為「出版效應」(publication effect),因為具有統計顯著的結果會被寫進期刊與圖書,而不具統計顯著的結果則無法得到版面。
對抗選擇性資料收集與選擇性報告的解方
解方 | 說明 |
運用常識 | 若特異功能真的存在,賭城已破產。 |
用新數據重新測試 | 請得到高分的受測者重新測試,通常測受結果,分數都會下降,當初的高分只是幸運猜測的選擇性報告而已。 |
常見臨床試驗法 (Ref: https://reurl.cc/kVWmDL )
單盲 | 雙盲 | 三盲 |
對於研究對象的分組及所施加的處理因素(如選用藥物)情況,只有研究者知道,而受試對象不知道 | 受試對象和試驗執行者(干預措施執行者及結果測量者) 雙方均不知分組情況,不知道試者接受的是哪一種干預措施 | 受試對象、試驗執行者和資料分析與報告者三方均不知道受試者接受的是哪一種干預措施,全部採用編號密封 |
方法簡單,容易進行 | 臨床試驗最常採用的一種盲法形式,可以有效避免受試對象和試驗執行者主觀的偏倚因素對試驗結果的影響 | 可以使偏倚減到最小的程度 |
單盲不能避免研究方主觀因素造成的影響。主管醫生可能通過許多方法去影響患者的療效, 比如,醫生對接受新療法的患者觀察特別仔細,護士對新療法組患者更加關心和熱情,這些都可能影響或暗示受試對象產生不同的反應。 | 有特殊副作用的藥物容易被破盲;雙盲試驗不適用於危重患者。 | 儘管三盲試驗是減少偏倚最有效的方法,但在實際工作中使用並不普遍。在許多臨床研究中,醫師既是試驗設計者與觀察者,也是資料分析和結果評價者,很難真正做到三盲。 |
假設檢定流程
假設檢定流程 | 說明 | |
提出相關的虛無假設和對立假設 |
| |
選擇檢定統計量 |
| |
選擇顯著水準並決定決策法則 |
| |
比較樣本統計量與臨界值並下結論 |
| |
單一樣本 t 檢定 (Ref: https://reurl.cc/1gLxEp )
分析資料 |
|
檢驗流程 |
R 語言 |
> # 抽樣高三甲班級學生的身高 > height <- c(173, 168, 185, 176, 181, 168, 159, 159, 171, 165) > > # 全校平均身高 > height_avg <- 172 > > # 常態性檢定 (p-value > 0.05 代表符合常態分佈) > shapiro.test(height) Shapiro-Wilk normality test data: height W = 0.95916, p-value = 0.7762 > > # 單一樣本 t 檢定(p-value > 0.05 沒有顯著證據顯示高三甲班級身高與全校平均身高有差異) > t.test(height, mu = height_avg) One Sample t-test data: height t = -0.55203, df = 9, p-value = 0.5944 alternative hypothesis: true mean is not equal to 172 95 percent confidence interval: 164.3532 176.6468 sample estimates: mean of x 170.5 |

獨立雙樣本 t 檢定 (變異數相同) (Ref: https://reurl.cc/1gLxEp )
分析資料 |
|
檢驗流程 |
R 語言 |
> # == 獨立雙樣本 t 檢定 == > # 抽樣學生的身高 > class_a_height <- c(173, 168, 185, 176, 181, 168, 159, 159, 171, 165) > class_b_height <- c(150, 189, 194, 171, 173, 188, 162, 180, 166, 170) > > # 常態性檢定 (p-value > 0.05 代表符合常態分佈) > shapiro.test(class_a_height) Shapiro-Wilk normality test data: class_a_height W = 0.95916, p-value = 0.7762 > shapiro.test(class_b_height) Shapiro-Wilk normality test data: class_b_height W = 0.96751, p-value = 0.8669 > > # F 檢定 - 檢查兩邊的母體變異數是否有差異 (p-value > 0.05 代表母體變異數相同的假設成立) > var.test(class_a_height, class_b_height) F test to compare two variances data: class_a_height and class_b_height F = 0.39884, num df = 9, denom df = 9, p-value = 0.1871 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 0.09906512 1.60570981 sample estimates: ratio of variances 0.3988356 > > # 獨立雙樣本 t 檢定(變異數相同)(p-value > 0.05 沒有顯著證據顯示兩班的學生平均身高有差異異) > t.test(class_a_height, class_b_height, var.equal = TRUE) Two Sample t-test data: class_a_height and class_b_height t = -0.74674, df = 18, p-value = 0.4649 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -14.491104 6.891104 sample estimates: mean of x mean of y 170.5 174.3 |

獨立雙樣本 t 檢定 (變異數不同) (Ref: https://reurl.cc/1gLxEp )
分析資料 |
|
檢驗流程 |
R 語言 |
> # == 獨立雙樣本 t 檢定 == > # 抽樣學生的身高 > class_a_height <- c(173, 168, 185, 176, 181, 168, 159, 159, 171, 165) > class_b_height <- c(174, 178, 175, 174, 170, 178, 175, 173, 175, 173) > > # 常態性檢定 (p-value > 0.05 代表符合常態分佈) > shapiro.test(class_a_height) Shapiro-Wilk normality test data: class_a_height W = 0.95916, p-value = 0.7762 > shapiro.test(class_b_height) Shapiro-Wilk normality test data: class_b_height W = 0.9227, p-value = 0.38 > > # F 檢定 - 檢查兩邊的母體變異數是否有差異 (p-value > 0.05 代表母體變異數相同的假設成立;p-value ≤ 0.05 代表母體變數不同) > var.test(class_a_height, class_b_height) F test to compare two variances data: class_a_height and class_b_height F = 13.158, num df = 9, denom df = 9, p-value = 0.0007116 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 3.268364 52.975705 sample estimates: ratio of variances 13.15842 > > # 獨立雙樣本 t 檢定(變異數不同)(p-value > 0.05 沒有顯著證據顯示兩班的學生平均身高有差異異) > t.test(class_a_height, class_b_height, var.equal = FALSE) Welch Two Sample t-test data: class_a_height and class_b_height t = -1.4191, df = 10.36, p-value = 0.1852 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -10.250745 2.250745 sample estimates: mean of x mean of y 170.5 174.5 |

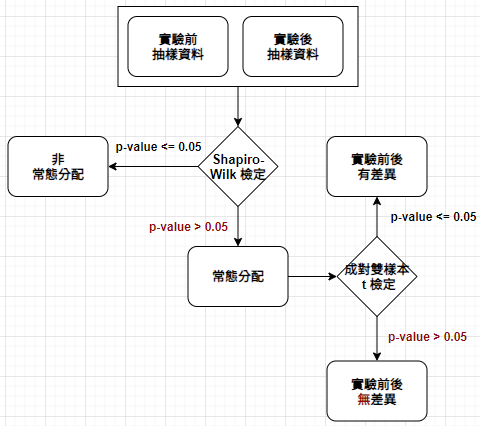
成對雙樣本 t 檢定 (Ref: https://reurl.cc/1gLxEp )
分析資料 |
|
檢驗流程 |
R 語言 |
> # == 成對雙樣本 t 檢定 == > # 長期運動前後的體重 > before <- c(70, 87, 84, 76, 67, 66, 83, 46, 71, 88) > after <- c(72, 91, 84, 79, 69, 69, 84, 48, 71, 90) > > # 常態性檢定 (p-value > 0.05 代表符合常態分佈) > shapiro.test(before) Shapiro-Wilk normality test data: before W = 0.90258, p-value = 0.2338 > shapiro.test(after) Shapiro-Wilk normality test data: after W = 0.90852, p-value = 0.271 > > # 成對雙樣本 t 檢定)(p-value > 0.05 沒有顯著證據顯示運動前後體重有差異異;p-value ≤ 0.05 代表運動後對體重有差異) > t.test(before, after, paired = TRUE) Paired t-test data: before and after t = -4.6696, df = 9, p-value = 0.001169 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -2.8204382 -0.9795618 sample estimates: mean of the differences -1.9 |
No comments:
Post a Comment