第十九章 何時相信,何時懷疑 (When to Be Persuaded and When to Be Skeptical)
被模式誘惑/具有誤導性的資料/變形的圖像/缺乏思考的計算/尋找混雜因素/手氣好/回歸平均值/平均定律/德州神槍手/當心經過剪裁的資料/缺乏理論的資料僅僅是資料而已/缺乏資料的理論僅僅是理論而已/美好的出生日
【模式誘惑】相關、趨勢和其他模式本身無法證明任何事情,如果沒有合理的解釋,任何模式僅僅是一種模式而已,每一個理論都須接受新資料的檢驗。

【選擇性偏誤 (selection bias):此偏誤發生於收納受試者時,「精挑細選」出的受試者無法代表母群體,「收納」與「未收納」到研究的對象有系統性差異 (systematic difference)。例如,二戰期間,結束轟炸任務的英國皇家空軍 (RAF, Royal Air Force) 戰機,受傷的彈孔多位於機翼與機尾,應加強防護這兩個位置;無法成功返航的都是被攻擊到駕駛艙與油箱位置的戰機,這兩個地方才是最需要加強防護的位置。沒看到的資料與看到的資料一樣重要,甚至更加重要。為了避免倖存者偏差,應當從過去的資料開始,並展望未來。

留意變形的圖像,會誤導你判斷:視覺化圖表不僅是一種藝術,更是為沒耐性的人帶來樂趣。有用的視覺化圖表可以準確且一致性地展示資料,協助我們理解;垃圾圖表則會分散注意力,使我們感到困惑與煩躁。垃圾視覺化圖表檢查清單



【缺乏思考的計算,當心膚淺的比較】人有一種自然傾向,僅關注計算結果是否準確,而不深究這個計算是否正確與合理。隨著人口成長,許多人類活動也會跟著增長,包含看電視時間、吃橘子的人數、死亡人數等。資料間毫不相關,但它們之間存在統計相關性,因為它們都會隨著人口增加而增長。看電視不會導致我們吃橘子,吃橘子不會導致死亡。在統計學中,相關性 ≠ 因果關係。不管兩者相關性多高,在做出判斷前,都需要合理的解釋。(Ref: https://reurl.cc/4y7kYK )

【小心干擾因素】干擾因素常存在於觀測性研究中,此時我們無法控制人們的選擇。干擾因素也存在於實驗環境中,因為研究人員有時也會忘記控制某個干擾因素。
【不要相信手氣說】我們喜好在資料中尋找模式,並為其編造理由,這是無法避免的事情。因此,我們很容易相信好手感與差手感的說法,進行相信手感會影響成功機率。記住,即使在隨機的拋硬幣實驗中,也會出現僅僅來自巧合的、引人注目的連續成功和連續失敗現象。好手感與差手感很可能確實存在,但它的差異比我們想像要小的許多。每次投籃與之前沒有關係,只是出現巧合地連續現象。優秀的狀態無法確保連續成功,糟糕的狀態也不保證連續失敗;優秀或糟糕的狀態也許僅是運氣而已。
【回歸均值】當學術能力和運動能力等特點得不到完美測量時,觀測到的表現差異會誇大實際能力差異。表現最優秀的人與平均水準的距離,很可能不像看上去那樣遙遠,表現最糟的人也是如此。因此,他們隨後表現將回歸均值。回歸均值也不是意味能力像均值收斂、大家很快會有平均水準,它只意味著,極端表現在經歷好運和壞運的群體間輪換。回歸均值也不代表成功和不成功的公司會走向令人沮喪的平庸。
【平均定律】當你在玩 21 點 (blackjack) 時,是否曾經連續拿了很多手壞牌,使得你增加賭注,認為情勢隨時可能改變,你就陷入賭徒謬誤 (Gambler’s Fallacy),以為連續拿了好幾次壞牌,拿到好牌的機率會增加。套用到純粹機率的遊戲上時,會是一連串「獨立事件」,事件間彼此毫無關係,每個個別的結果都與它之前的結果無關,這個事實經常被總結為「骰子沒有記憶」。想改變運氣,通常需要改變自身的行為。面試一直被拒絕,並不會提高未來錄取機率,相反地,這只是更加證明此人不適合此職缺,應當考慮如何表現得更好,或者考慮申請不同工作。正負相抵只是一個笑話,不是值得信賴的規律。我們正在經歷壞運時,總會希望能轉運。我們的壞運可能不會持續,但發生在我們身上的壞事,並不會自動提高好事的可能性。(Ref: Statistics Hacks)
【德州神槍手謬誤 (Texas sharpshooter fallacy)】又稱為先射箭再畫靶,是一種因果謬誤,原用以形容流行病學上的集群錯覺,後衍伸泛指將統計上隨機產生的群集獨立出來,宣稱有統計顯著性的謬誤。通俗地講,就是在大量的數據/證據中刻意地挑選出對自己的觀點有利的數據/證據,而將其餘對自己不利的數據/證據棄之不用。(Ref: https://reurl.cc/v52z7a)
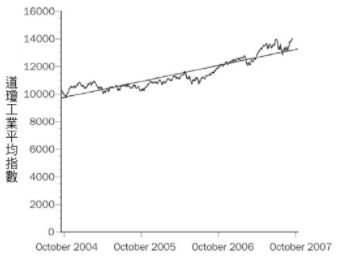
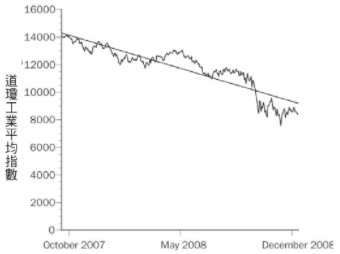
【當心經過剪裁的資料】每當有人出示奇特起迄時間點的資料時,都應保持懷疑。如果起迄點看是去是仔細研究資料後所做出的選擇,這樣的選擇很可能是為了扭曲歷史紀錄,用以獲得合乎邏輯的完美解釋。
【缺乏理論的資料,就只是資料而已】只要夠努力,即使面對隨機生成的資料,也可以找到模式,不管這種模式有多明顯,都需一個合理的理論來解釋,否則,就只是巧合而已。
【缺乏資料的理論,就只是理論而已】不管這一項研究是誰做的,都需要通過常識性檢驗,而且需要使用沒有被資料採集污染的無偏差資料來做檢驗。在經過可靠資料檢驗前,理論僅是一種猜測。