排序 (Sorting) - 依照順序排列
在 1960 年代,有一項研究估計,全世界的電腦運算資源有 ¼ 以上用於排序。這點其實可以想見,因為排序對於處理各種資訊都非常重要。無論是找出最大或最小、最常見或最罕見、紀錄、製作索引、挑出重複物件,或者單純只要找出需要的資料,各種工作一開始通常都得先排序。
追根究柢,排序的主要理由就是以好用的方式呈現物件,因此排序也對人類的資訊經驗極為重要:
1955 年 J.C. Hosken 在史上第一篇發表的排序論文中寫到:「為了降低每單位的成本,人類通常會加大運作規模。」這就是所謂的規模經濟,但是規模卻造成排序災難。排序規模加大時,排序的單位成本不減反增,導致嚴重的負規模經濟。例如,假設書架上有 100 本書,另外有兩個書架各 50 本,排好前者的時間一定大於後者,因此需要整理的書以及每本書可以放的空格,都多了一倍。需要處理的東西越多,狀況就越糟。
要減少排序的辛苦和麻煩,重點是減少排序對象的數量。
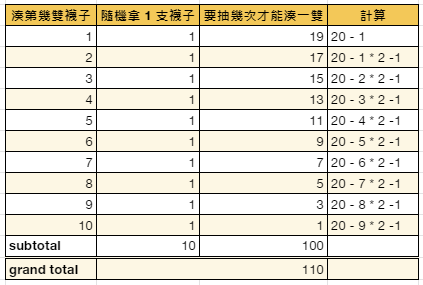
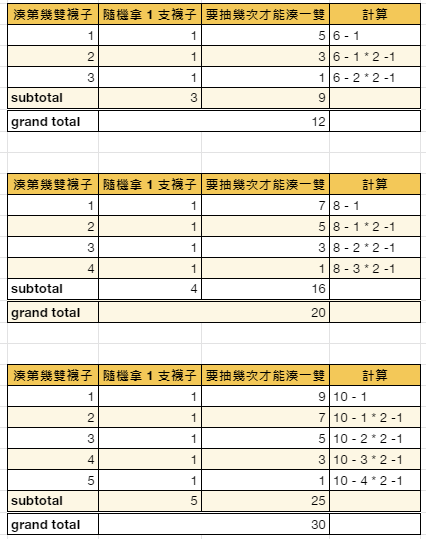
大O符號 (Big-O Notation),又稱為漸進符號,是用於描述函式漸近行為的數學符號。更確切地說,它是用另一個(通常更簡單的)函式來描述一個函式數量級的漸近上界。在數學中,它一般用來刻畫被截斷的無窮級數尤其是漸近級數的剩餘項;在電腦科學中,它在分析演算法複雜性的方面非常有用。假設你要辦個晚宴,邀請 n 名賓客:

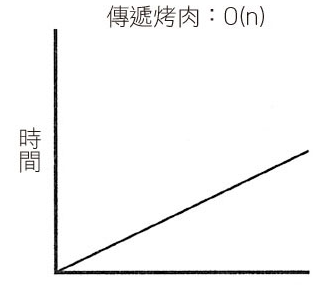
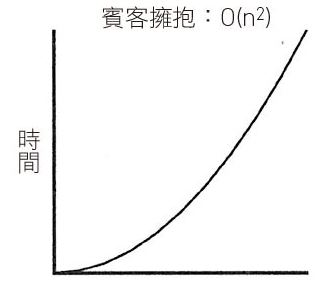

氣泡排序法 (Bubble Sort) 與插入排序法 (Insertion Sort)


上述兩個看似合理且直覺的排序方法,搜尋時間都是平方時間 (quadratic time, O(n2)),排序對象一多就難以負荷。合併排序 (merge sort) 就是用來解決上述難題,它的複雜性介於線性時間和平方時間之間,更精確地說是線性對數時間 (linearithmic time, O(n log n))。屬於 Divide and Conquer 演算法,把問題先拆解 (divide) 成子問題,並在逐一處理子問題後,將子問題的結果合併(conquer),如此便解決了原先的問題。

(Ref.: https://reurl.cc/bzEEnl)
排序與運動賽事的類比
排序與搜尋的權衡:拿你絕對不會搜尋的資料來排序是浪費時間,搜尋沒排序過的資料則效率極差。排序資料所花的心力是先制行動,目的是讓我們日後不用花費心力搜尋資料。真正的平衡點應取決於狀況的確實參數,但如果說排序唯一價值是輔助日後查詢,就可以看出一個驚人事實:寧亂勿整。例如,現在電子郵件軟體的搜尋功能已經相當完善,當搜尋成本降低時,排序的價值就會跟著降低。
不排序資料或許可以想成一種延遲行為,把責任推給未來的自己,讓他連本帶利地付出逃避的代價。不過整個狀況其實更加微妙,有時候混亂不只出於偷懶,而是最佳選擇。
在奧運場上,拳擊選手必須冒著腦震盪的風險,比 O(log n) 次才能舉起金盃 (通常四到六次);馬拉松選手則只需比一次。如果能以一個簡單數值來評量表現,就能以常數時間演算法來決定名次。從只能呈現排名的序數改成基數 (直接指定評定水準的方式),就能自然地依序排列,例如 Fortune 500 的排名,不需公司間兩兩比較,只要有基準就能解決排序規模擴大產生的運算問題。
在小規模族群中,線性對數次數的打鬥或許行得通,自然界的族群也經然如此。但再藉由兩兩比較決定地位的領域中,衝突次數將隨群體數目成長而快速增加。要讓成千上萬、甚至數百萬個群體生活在同一空間中,就必須跳脫出來,從序數變成基數 (或稱為基準)。人類和猿猴、雞等動物的差別是,以競賽取代打鬥。
假設你是位正在撰寫論文的研究生,已知圖書館有數本需要隨時可參考的書籍,你會希望借閱這幾本書,放在宿舍的書桌上,而非需要參考時還要特地去圖書館一趟。此時,你的書桌就是電腦領域提到的 cache (快取),當書桌上有可重複利用的書籍,你書桌的價值就越高;當你越常回圖書館找資料,工作進度越慢,書桌利用率越低,書桌價值就越低。
No comments:
Post a Comment