貝氏法則 (Bayes’s Rule) - 預測未來
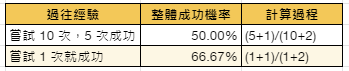
Laplace’s Law (拉普拉斯定律) 計算期望值:假設買 n 張彩券有 w 張中獎,期望值= (w+1)/(n+2)。想算出公車遲到機率嗎?你參加的壘球隊的贏球機率?只要算一下過往發生次數 + 1,再除以機會數 + 2 即可。拉普拉斯定律的優點在於,無論只有一個資料點或是有數百萬個資料點,它一樣有效。例如,地球上已經連續看見太陽約 1.6 億次,明天太陽還是會升起的機率與 100% 無差別。
貝氏定理 (Bayes' Theorem)
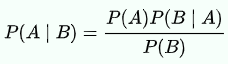

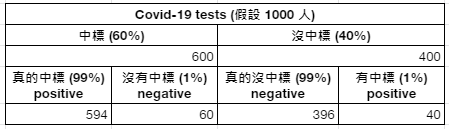

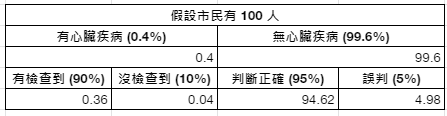
哥白尼原理 (Copernican principle):相較於貝式定理知道事前機率,若面臨「無提示性事前機率」(uninformative prior),適合運用哥白尼原理來做推測。

幂律分布 (Power Law Distribution) 的概念,類似80 / 20 法則。例如,最有名的明星收入與影響力比所謂的二線明星多非常多,而二線明星又比那些剛出道的小咖多得多。Peter Thiel 在《從零到一》這本書中提到,在創投的領域,很可能回報最豐厚的那家公司比剩下其他全部加起來還多;而第二豐厚的則比第一以外的全部加起來還多,所以「公司排名vs投資回報率」呈現類似於下圖 (Ref: https://reurl.cc/e9Db2Q)

常態分布 vs 幂律分布

貝氏法則告訴我們,要以有限的證據進行預測時,最重要的條件是擁有正確的事前分布,也就是知道哪種分布可為我們提供證據。因此要做出正確預測,基本條件是知道遇到的是常態分布還是幂律分布,對於這兩種分布,貝氏法則分別提供簡單、但完全不同的預測規則。
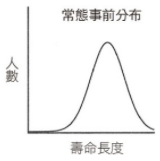
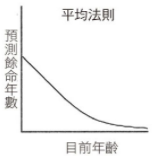
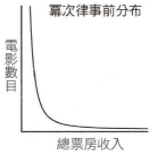



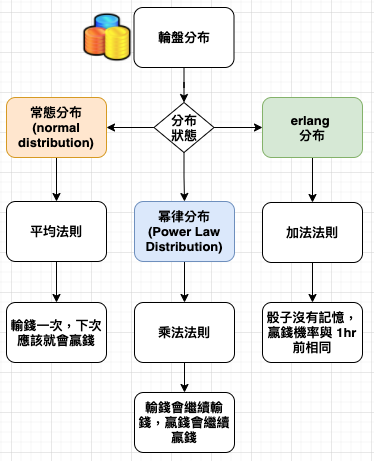
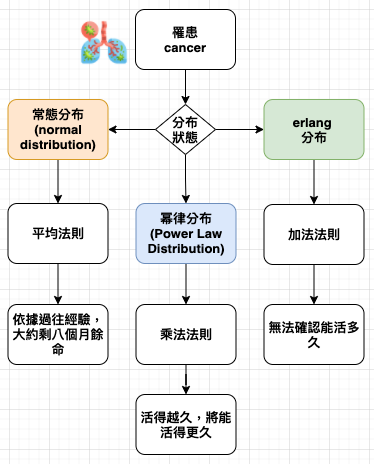
在沒有適當的事前分布的情況下,我們就無法做出準確預測。例如,預測法老王的在位期間,這就是 erlang 分布,一般人很少接觸這類資料,沒有機會建立這類時間範圍的直覺,當然無法準確預測。但是,我們對人類壽命有精確的事前分布,故能精準預測。由此可見,適當的事前分布是準確預測的必要條件。
棉花糖測驗

在另一組棉花糖實驗中,因幼兒無法信任實驗者,無法確定是否會回來,幼兒大多會選擇吃掉,而非等待。學習自我控制很重要,但在成人經常陪同且值得信任的環境中長大,同等重要。

如同貝式定理所述,要做出準確預測的最佳方式,是確實了解我們要預測的事物,但因平面媒體、電視新聞、社群媒體的問世,讓這個挑戰越來越大。例如,媒體不斷放送飛機失事新聞,讓你忽略車禍喪命的人數遠高於飛機失事人數;美國凶殺案在 1990 年代降低 20%,但此段時間美國槍枝暴力案件的見報率卻提高 600%。如果你想要成為具有正確直覺的貝氏統計學家,若你想自然地做出正確預測,不需思考應採用哪個預測法則,就必須好好保護你的事前分布,你該做的反而是違反直覺地少看新聞。
每個決定都是一種預測,預測我們對陌生事物的喜愛程度、預測某個趨勢會怎麼發展、預測較少走的路會怎麼樣。殘酷的是,每次預測都必須考慮兩件完全相反的事:我們知道什麼與不知道什麼。預測是試圖提出一個理論,解釋我們目前擁有的經驗,同時預測未來的某些事物。好的理論能同時滿足兩個要求,但每項預測都身負雙重責任,也造成難以避免的矛盾。
No comments:
Post a Comment