隨機性 (Randomness) — 什麼時候該讓機率決定
乍看之下,隨機性似乎與理性背道而馳,代表我們放棄此問題,被迫採取的手段。其實不是這樣,隨機性在電腦科學中扮演令人驚訝的角色,且越來越重要,且證明在面對極為困難的問題時,運用機率可能是謹慎又有效的解決方法。事實上,有時我們別無選擇。
隨機性演算法未必能提出最佳解,但它不用像確定性演算法那麼辛苦,只要有計畫地丟幾個硬幣,就能在短短時間內提出相當接近最佳解的答案。隨機性演算法用於特定問題的效果,甚至超越最好的確定性演算法。問題的最佳解決方法有時候是交給機率決定,而不是自己試圖推出答案。這章將要告訴你依靠機率的時機、方式,以及仰賴的程度。
Estimate Pi by Chance (以機率估算圓周率):統計學家很喜歡認為任何重要的事都可透過統計學來發現。實際上可能是真的,因為我們發現,你甚至可以使用統計學來估計科學中最重要的基本數值,也就是 pi (圓周率)。Buffon’s Needle Problem 發現,針與線相交的機率是 2。

抽樣過程一定會有誤差,但我們可透過確保樣本為隨機,以及取得更多樣本,以減少誤差。在沒有其他方法能得出答案時,抽樣至少可以提供答案,就這點而言,抽樣優於執行分析。隨機性最令人驚奇的能力,是它可用在機率似乎無用武之地的地方,即使我們想知道的答案只有是否或真假,沒有模糊空間,擲幾次骰子似乎也能提供部分解答。
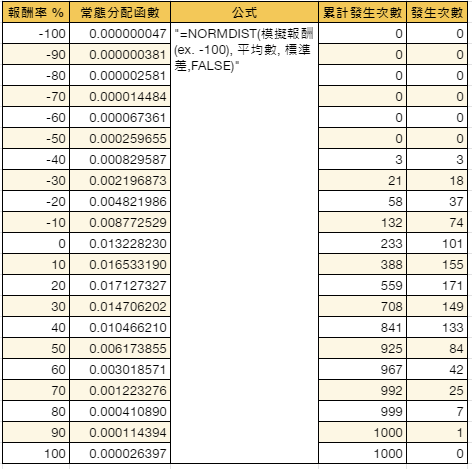
蒙地卡羅模擬法 (Monte Carlo Simulation) 是一種數值方法,利用亂數取樣 (Random Sampling) 模擬來解決數學問題。在數學上,所謂產生亂數,就是從一開始給定的數集合中選出的數,若從集合中不按順序隨機選取其中數,稱為亂數,若是被選到的機率相同時,稱為均勻亂數。例如擲骰子, 1 點至 6 點骰子出現機率均等。 舉凡在所有目前具有隨機效應的過程,均可能以蒙地卡羅方法大量模擬單一事件,藉統計上平均值獲得某設定條件下實際最可能測量值。 蒙地卡羅模擬法,是基於大數法則的實證方法,當實驗的次數越多,其平均值也就會越趨近於理論值。



我們已習慣數學是個說一是一的領域,說某個數字「可能是質數」或「幾乎可能是質數」,會讓人感到奇怪。實際上,在網際網路連線和數位交易用來加密的現代密碼系統中,偽陽性 (false positive) 比例不到 1024 分之一,這個數字是小數點後有 24 個 0,也就是數目等於地球上所有砂粒的質數中,只有不到一個假質數。透過 Miller-Rabin 質數測試,確實不能 100% 確定,但能夠很快地確定一個數字很可能是質數。
要理解一個過於複雜、無法理解的事物,仔細研究隨機樣本可能是最有效的方法。碰到接龍遊戲、核分裂、質數性測試或公共政策等,這類數字龐大到無法掌握、複雜棘手到無法直接處理的事物,蒙地卡羅法的電腦科學家提出的「抽樣方法」,可以說是最簡單且最好的解決方案。
John Stuart Mill (英國哲學家與經濟學家):沒有事情是絕對確定的,但事情的確定程度已經足夠人活下去了。
布隆過濾器 (Bloom filter) 是1970年由 Bloom 提出的。它實際上是一個很長的二進位向量和一系列隨機對映函式。布隆過濾器可以用於檢索一個元素是否在一個集合中。Bloom filter 的優點是空間效率和查詢時間都遠遠超過一般的演算法,缺點是有一定的誤辨識率和刪除困難。Bloom filter 是一個 data structure 用來提升速度及記憶體使用的效率。這個 data structure 是 probabilistic data structure,它可以判斷某個元素 (element) 是否在某個 set 內。此方法雖然存在誤差率,有可能把不屬於這個 set 的元素誤認為屬於這個 set (False Positive),但不會把屬於這個 set 的元素誤認為不屬於這個 set (False Negative)。【應用1】 Tinder 會根據你身處的地方及個人要求作出配對,為了避免重複出現同一選擇 (已和你配對或已被你拒絕的對象),系統會將已經出現的選擇加入 Bloom filter。這樣用戶就不用又再次見到相同的對象;【應用 2】任何一個 Unique ID 系統都會為新的註冊用戶產生獨一無二的號碼。假如在短時間有大量用家來註冊成為用戶,就會為數據庫帶來負擔。為了減輕數據庫負擔,可以利用 Bloom filter 來檢查某個註冊號碼是否已經存在。(Ref: https://reurl.cc/e9zKnQ)
運用隨機法,想辦法從局部最大值,變成整體最大值


無論是抖動、隨機重新開始、或是接受解決方案偶而變糟,隨機性用於避免局部最大值的效果都很好。機率不只是處理困難最佳化問題的可行方法,在許多狀況下還是必要方法。從模擬退火法可以得知,你應盡早使用隨機性,並快速離開隨機的狀態,隨時間而降低隨機性,停留在接近結冰的時間最久。壓住火氣,不要急躁。
1971年出版的小說《骰子人》(Dice Man)講述了一位精神科醫生根據擲骰子做出日常決策的故事。小說中的敘事者因總是擲骰子做決定,最後很快陷入絕境。作者 George Cockcroft 的人生有段時間也處於「擲骰子」狀態,跟家人一起開著帆船,在地中海漫無目的旅行,然而到某一天,他的退火程序結束,停留在某個局部最大值,在某個湖過著愜意的日子,現在以 80 多歲,依然知足地住在那裏。他向《衛報》表示:「你一旦到了讓你感到快樂的地方,再大幅改變就太傻了 (stupid to shake it up and further)。」
No comments:
Post a Comment