過度配適 (Overfitting) — 少,但是更好
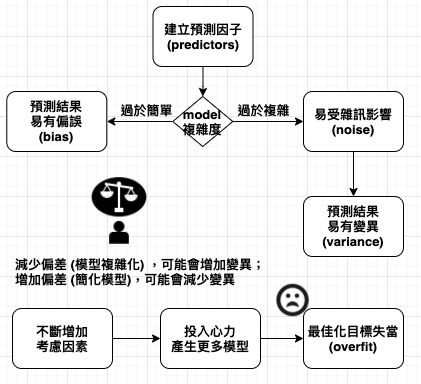
模型如果太簡單 (ex. 單因素模型所形成的直線),可能無法表現資料的主要型態;模型如果太複雜 (ex. 九因素模型),又會太容易受到取得資料點的影響,這就是統計學家提到的 overfit (過度配適)。在機器學習領域有個十分重要的事實,使用因素較多、較複雜的模型,未必能得到較好的預測結果,複雜型帶來的問題,反而使我們的預測變得更糟。

若樣本資料極具代表性,採用最複雜的模型會是個好辦法;若樣本資料有偏差,採用最複雜的模型就會容易遭受雜訊 (noise) 影響,遭遇過度配適 (overfit) 問題。overfit 就是資料的偶像崇拜,因為我們只注意到測量的資料,反而忽視真正重要的東西。
偏差 (bias) 與變異 (variance) 的兩種模型誤差是互補的,減少偏差 (模型複雜化) ,可能會增加變異;增加偏差 (簡化模型),可能會減少變異。在量子力學中,海森堡 (Heisenberg) 的測不準原理,陳述如果確定粒子的位置,將使它的動量不確定性增加;相反的,如果精確測量粒子的動量,將使它的位置的不確定性增加。同樣地,偏差與變異的權衡,呈現了模型優異程度的基本界線。
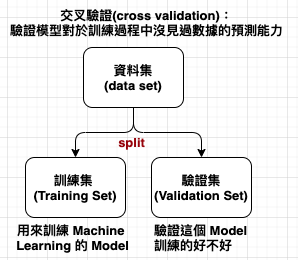
如何揪出 overfit ? 透過交叉驗證 (cross validation) 可以驗證是否出現 overfit,驗證模型對於訓練過程中沒見過數據的預測能力,可以避免依賴某一特定的訓練和測試資料產生偏差。例如,學校會利用標準化考試 (ex. 段考、期末考) 來驗證學生學習成效,但有可能學生發展出考高分的技巧以適應標準化考試,出現 overfit 的現象;此時,可隨機挑選學生 (ex. 一班一個人) 來做非標準化考試 (ex. 口試或作文),若兩者分數有差異,代表學生技能已 overfit 現有考試機制。透過交叉驗證,可以避免遇到抽到某些資料驗證出來覺得模型訓練得還不錯,但換抽另一批資料來驗證就又覺得模型訓練的很糟糕的狀況。

以統計學家的觀點,overfit 是對已知實際資料過度敏感的症狀 (ex. 學生很熟悉會考的方向),解決方法很直接,抑制想找出完全符合模型複雜度的念頭。在統計學和機器學習中,Lasso 演算法對因素權重施加向下的壓力,最多可使它變成 0,只有對結果有明顯影響的因素才能繼續保留在方程式中,因此,一個 overfit 的九因素模型,可簡化到只剩下少數幾個重要因素,方程式也因此變得簡單穩定,增強統計模型的預測準確性和可解釋性。
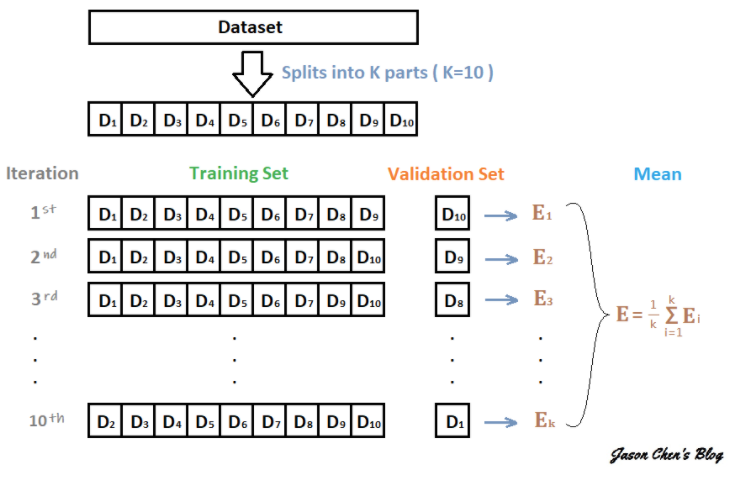
一般來說我們在做機器學習 (Machine Learning) 的時候,我們會習慣將資料集 (Dataset) 切割 (Splits) 成訓練集 (Training Set) 跟驗證集 (Validation Set)。顧名思義,Training Set 是用來訓練 Machine Learning 的 Model;而 Validation Set 則用來驗證這個 Model 訓練的好不好。顧名思義 K-fold Cross-Validation 就是將資料集拆分成 K 份做交叉驗證。交叉驗證的方法是將其中 K-1 份的資料當作訓練集,剩下來的那份做為驗證集,算出一個 Validation Error,接著再從沒當過驗證集的資料挑一份出來當驗證集,剛剛做過驗證集的資料則加回訓練集,維持 K-1 份做訓練、1 份做驗證,如此反覆直到每一份資料都當過驗證集,這樣會執行 K 次,算出 K 個 Validation Error,最後我們再將這 K 個 Validation Error 做平均,用他們的平均分數來做為我們評斷模型好壞的指標。(https://reurl.cc/OXjOXA)
語言也形成另一種 Lasso 演算法,話講得越多,花的力氣越大,聆聽者的注意力負擔也會加劇,你應降低講話的複雜度;business plan 被壓縮為簡單扼要的簡報、人生建議必須簡短有趣才能廣為流傳。凡事必須通過 Lasso 演算法,人們才能牢牢記住它。
面對複雜的真實生活,放棄理性模型,採用單純的試探法,反而是最理性的選擇。談到投資組合管理,除非你對自己掌握的資訊有十足把握,否則還是完全忽略這些資訊比較好,只要估計稍有誤差,就形成差別很大的資產配置;股債各半的資產配置,完全忽略歷史資料,不會有 overfit 問題。少即是多 (less is more) 與減少 overfit,將是人類社會的重要指南。
毫無頭緒時,最簡單的計畫就是最好的計畫。當我們的期望不確定、資料又有許多雜訊,最好的辦法就是從大處著手,以簡略方式思考。需要思考越深入時,用的筆就要越粗,麥克筆讓人無法鑽入細節,只能用來畫形狀、線條和方塊,讓你能專注於整體而非細節。
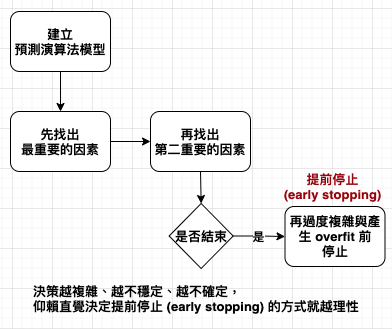
提前停止 (early stopping) 的重點,有時候不是在理性與直覺間做選擇。跟著直覺走,有時也是理性的解決方案。決策越複雜、越不穩定、越不確定,仰賴直覺決定提前停止 (early stopping) 的方式就越理性。
No comments:
Post a Comment