DNA 檢測公司 23AndMe 與 Ancestry.com 所使用的基因定序技術只有 0.1% 的錯誤率,乍看之下非常可靠。但我不能忘記,如果要檢驗的遺傳變異將近 1000 萬種,0.1% 的錯誤率代表預計會有約 1000 個錯誤。因此,兩家公司獨立做出的不一致結果,確實是個令人擔心、但不令人意外的結果。或許我們該擔心的是沒有獲得後續的醫療支援配套,只獲得檢測結果而已。
由於各家檢測公司採用不同的數學方法,所以對於那些個人基因組學健康報告所提出的風險數據,應該都要抱持懷疑態度。
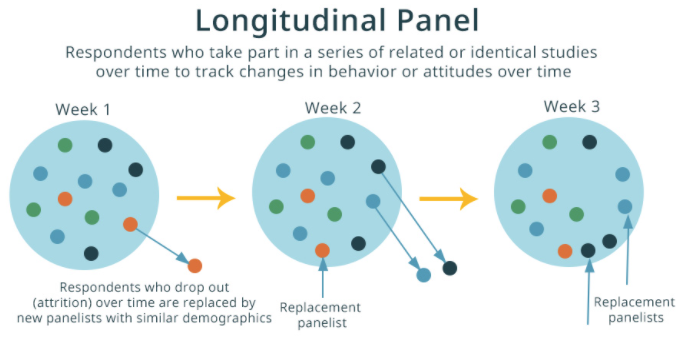
Longitudinal Study (貫時性研究) 意指在不同的時間點上,針對相同的主題、對象,所做的比較性研究。(https://reurl.cc/zWjeQk)

冷門賠率 (odds against) 與熱門賠率 (odds on)
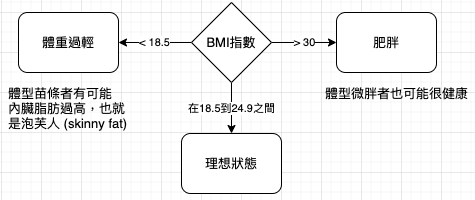
身體質量指數 (BMI, Body Mass Index) 又稱為凱特萊指數 (Quetelet index),是由一個人的體重和身高計算出的一個數值。BMI 的定義是體重除以身高的平方,以公斤/平方公尺為單位表示,由體重 (公斤) 和身高 (公尺) 得出。但 BMI 最大的問題,就是把肌肉與脂肪混為一談,瑞典健康機構 Amra 的負責人 Tommy Johansson認為在衡量內臟脂肪方面,BMI 作用很小。(https://reurl.cc/q1j5bp)
阿基米德想確認王冠是否以純金打造,得想出比對王冠的質和量的辦法。阿基米德的難題是,他既不能融化王冠,又得精確算出它的體積。🛀 直到他踏進公共浴池時,注意到水位升高的現象,才靈光一閃:要測量不規則的物體時,觀察他排出多少水就好。據說阿基米德極其興奮,連衣服都沒有穿,就急著跑回家,並一邊歡呼:「Eureka !」這希臘文的意思是「我知道了」,後來變成科學新發現的同義詞。《The Most Human Human》
阿基米德浮體原理 (Archimedes's principle):⛵ 物體在液體中所獲得的浮力,等於物體所排出液體的所受的重力。此一成就影響後世至深,遠勝揭露金匠的舞弊。

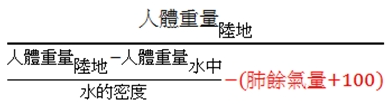
水中秤重法 (hydrostatics weighing 或 underwater weighing) 是運用阿基米德浮體原理,正確計算人類體脂 (https://reurl.cc/35lQDl)
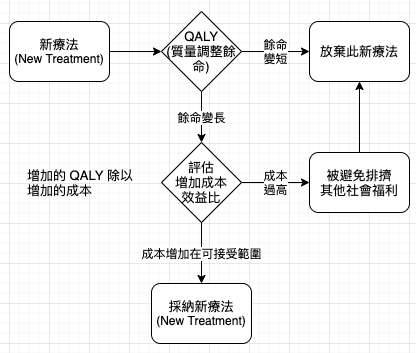
上帝公式 (God Equation):決定英國國家健保局會支付那些新藥的費用,實際上也是決定哪些病人可以活下來,哪些病人將死去 (https://reurl.cc/Ok8a8D)

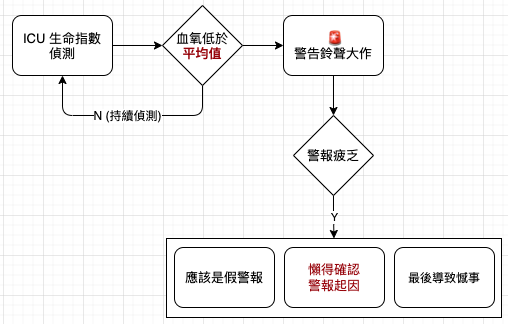
假警報通常是指,當警報被觸發,但並非出自原本想偵測的原因。這並不罕見,我們甚至因為太常聽到警報聲,產生「警報疲乏」而懶得因應。若懶得確認警報起因,這樣為何要安裝警報器呢?

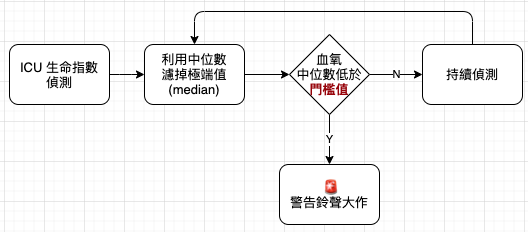
加護病房 (ICU, Intensive Care Unit) 有高達 85% 的警報是假警報,這不但讓醫護人員疲於奔命,有時甚至因為警報疲乏而懶得因應,最後導致憾事。透過中位數的過濾,降低 60% 的假警報,既能不影響病患安危,又能避免讓醫護疲於奔命。
算數平均數 (mean) 與中位數 (median) 的應用
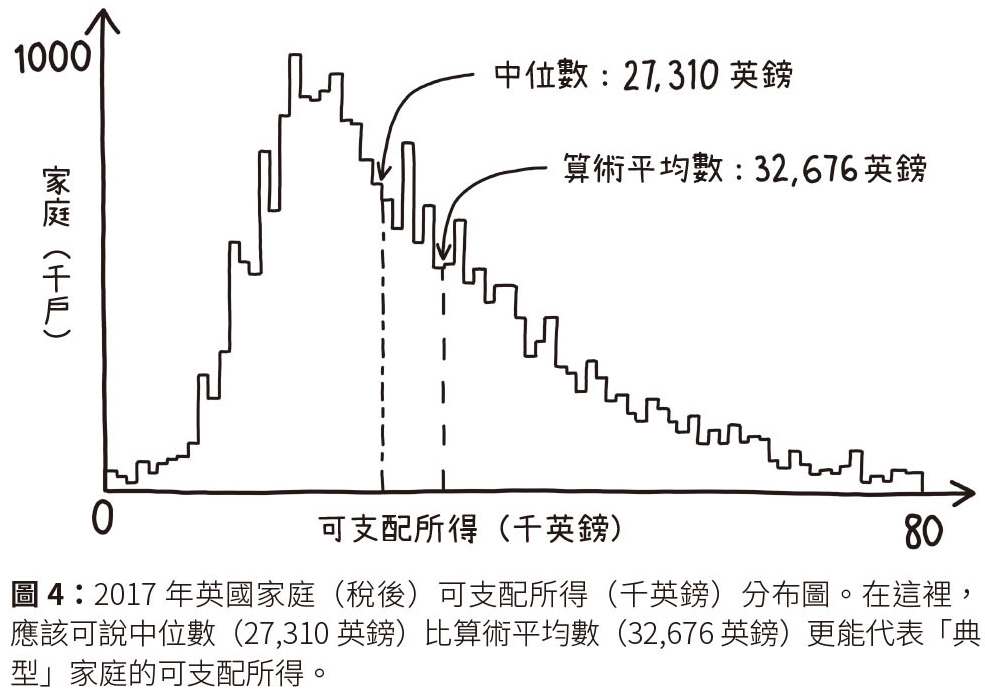
如何挑選 honest average 《Statistics Hacks》

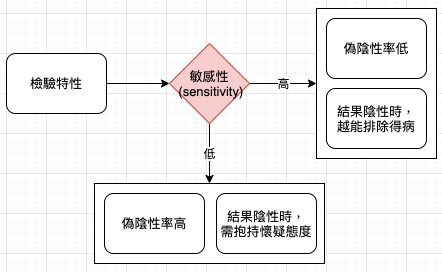
二元性 (binary) 檢測可以提供診斷用的篩選資訊,但病人經常會理解錯誤,有時甚至醫生也會。了解稱作「敏感度 (sensitivity)」和「特異性 (specificity)」的機率特徵能提供更為準確且 (有的時候) 令人安心的畫面。《HOW NOT TO BE WRONG》

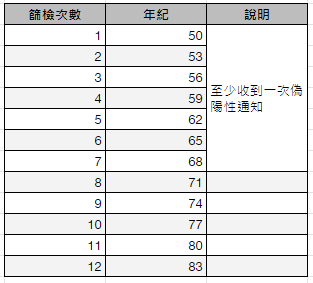
英國國家篩檢計畫 (National Screening Programme) 前負責人 Muri Gary 曾指出:「所有篩檢計畫都會造成傷害,只是有些也能帶來好處,而在帶來好處的計畫中,有些能以合理代價,帶來利大於弊的結果。」
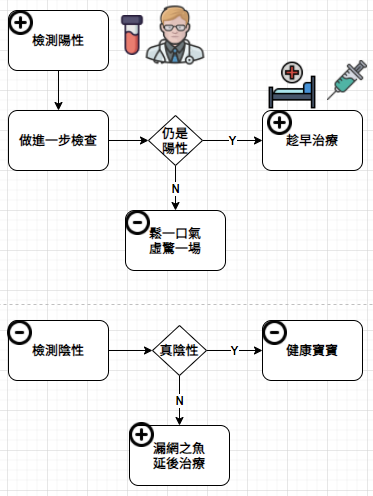
確定性假象 (illusion of certainty):在醫療篩檢中,偽陽性之所以會造成問題,部分原因在於我們對醫療檢測結果的深信不疑。我們想盡辦法,急著想要得到某個確定答案,忘了應該對相關結果抱持懷疑態度。
對於絕大多數健康的人來說,檢測「準確」代表這些人真的沒有病,是「真陰性」。由於未染病的人會有兩種檢測結果:真陰性與偽陽性,真陰性的比例越高,偽陽性的比例就越低,檢測就越準確。
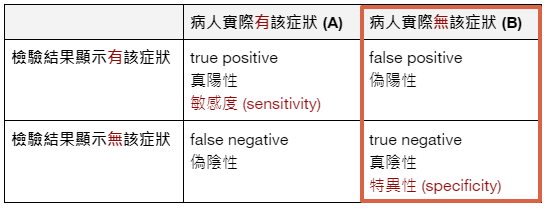
敏感性 (sensitivity) 與特異性 (specificity)

【缺乏思考的計算,當心膚淺的比較】人有一種自然傾向,僅關注計算結果是否準確,而不深究這個計算是否正確與合理。隨著人口成長,許多人類活動也會跟著增長,包含看電視時間、吃橘子的人數、死亡人數等。資料間毫不相關,但它們之間存在統計相關性,因為它們都會隨著人口增加而增長。看電視不會導致我們吃橘子,吃橘子不會導致死亡。在統計學中,相關性 ≠ 因果關係。不管兩者相關性多高,在做出判斷前,都需要合理的解釋。(Ref: https://reurl.cc/4y7kYK )

提高某項檢測精確度的方式,例如武漢肺炎的檢測,第一輪用快篩,盡可能抓出潛在陽性個案;第二輪針對陽性患者做 PCR 檢測,藉此剃除偽陽性個案。
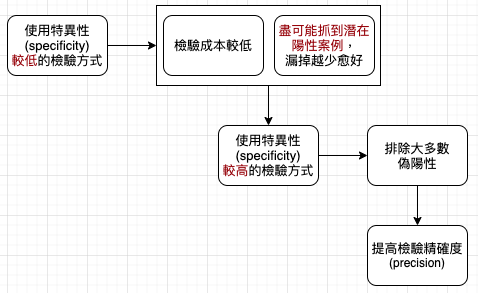
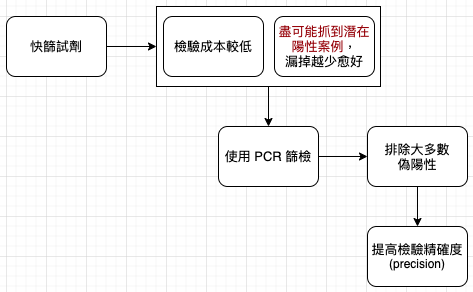
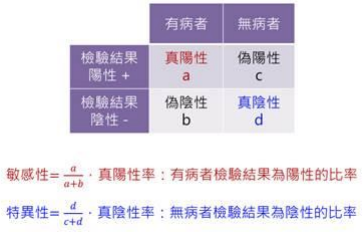
檢測有可能完全準確嗎?意即敏感性 (sensitivity) 與特異性 (specificity) 都是 100%,既能找出所有患病對象,而且完全不會找錯人。實務上,偽陽性與偽陰性呈現負相關:偽陽性越少,偽陰性就越多,反之亦然。有效的檢測會找出一個門檻值,在完全敏感性與完全特異性之間找到平衡,盡可能與兩者接近。
檢測必須做敏感性與特性的的折衷原因,是因為我們常常檢測的對象並非現象本身,而是一些替代對象,稱之為替代標記 (surrogate marker)。以居家懷孕檢測為例,檢測試紙並未進入子宮尋找是否有著床的胚胎,它是檢測 HCG 是否增加,HCG 就是扮演替代標記的角色。因為若有其他標記與替代標記太過類似,就可能觸發陽性結果。
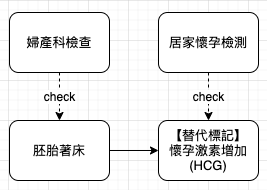
居家懷孕檢測出現陽性時,因我們檢查的是替代標記的原因,常會誤判懷孕,忽略惡性腫瘤刺激 HCG 的可能性

唐氏症檢查
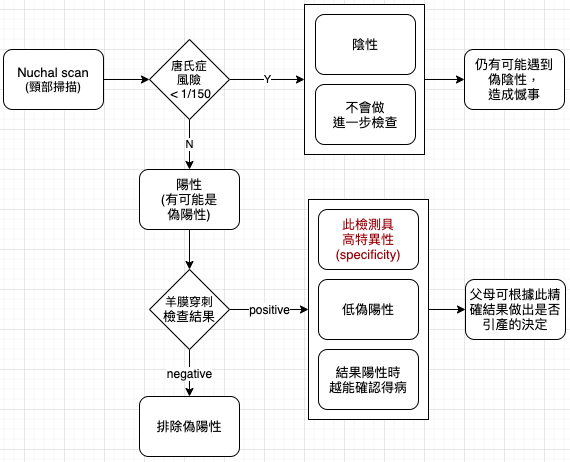
不論我們是否喜歡,都無法避免偽陽性與偽陰性。雖然靠著數學與科技,可以用像是過濾之類的工具在第一線就處理掉其中一些問題,但仍有些問題須靠我們自己解決。記住,篩檢並非最終診斷,需耐心等待第二輪更準確的追蹤檢查結果。
有些檢測或許沒有更進階的檢測工具,在此種狀況下,就算只是把同樣的測試再做一次,也能顯著提升精確度。

進行兩輪檢測以提升HIV 檢測精確度 (precision)

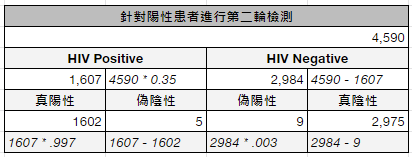
永遠不要害怕去詢問第二意見,事情清楚擺在眼前:就算是醫生這種公認的專家,總散發一種信心的假象,也不見得每次都能確實的掌握數字。
當你因為單一檢測結果感到焦慮時,請先去研究那項檢測的敏感性與特異性,計算結果錯誤的可能性。去質疑那些確定性的假象,把詮釋權重新抓回自己手中。
No comments:
Post a Comment