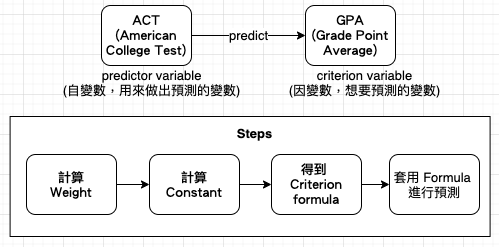
聖經密碼,也稱作 Torah 密碼 (妥拉,英文:Torah,可泛指猶太教的全部律法教條,尤指《猶太聖經》的首五卷書),最初指的是在《希伯來聖經·創世記》的開頭每隔50個字母跳讀,就可以拼出「Torah」一詞(意指《摩西五經》,即《創世記》、《出埃及記》、《利未記》、《民數記》及《申命記》),另外在《出埃及記》、《民數記》和《申命記》中亦是如此。這種現象後來被稱做等距字母序列(Equidistant letter sequences),簡稱「ELS」。ELS 密碼,由於 The Bible Code 一書的出版而聞名於世,書中作者聲稱這些密碼可以預言將來。此論點受到各方專家和許多宗教團體強烈質疑,且也不被教廷所認可。(Ref: https://reurl.cc/Dv5W9j )

等距字母序列(Equidistant letter sequences)的原理:從聖經第一個字母開始,尋找一種可能的跳躍序列,從1、2、3個字母,依序到跳過數千個字母,看能拼出什麼字,然後再從第2個字母開始,周而復始。一直到聖經最後一個字母。例如Rips ExplAineD thaT eacH codE is a Case Of adDing Every fourth or twelth or fiftieth to form a word得出隱含訊息為READ THE CODE。(Ref: https://reurl.cc/Dv5W9j )
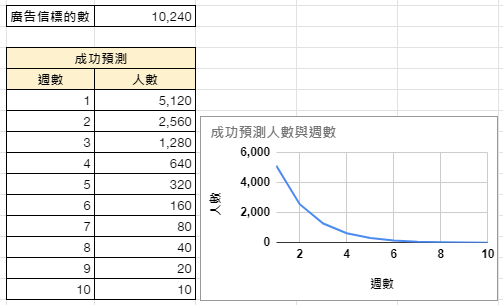
股票經紀人的套路:預測漲跌 10 次皆正確的機率是 (12)10=11024,表面上 10 次都矇對的機率為乎極微。但是以股票經紀人的角度看事情,局面就大為改觀。假設共有 10,240 人會收到他的股市預測廣告信,但是信件內容不太相同,在第一輪,5,120 人會收到上漲預測、另一群 5,120 人會收到下跌預測,收到錯誤預測的那群人就不會繼續收到廣告信;下一週 (第二輪),2,560 人會收到上漲預測、另一群 2,560 人會收到下跌預測,收到錯誤預測的那群人就不會繼續收到廣告信。經過 10 週,會剩下 10 個幸運兒,覺得這位股票經紀人料事如神,股票經紀從這 10 個人收取大量學費與佣金,但是對這 10 個人而言,過去的預測成績無法保證未來成果。
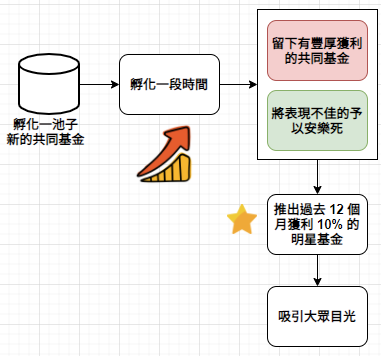
共同基金也是用相同的養、套、殺招式:連續股價預測成功 10 次、共同基金連續 12 個月獲利 10%,確實都是不太可能發生的事情。因為遇上不太可能發生的事,所以會產生誤判。宇宙很巨大,但只要你想注意奇妙而不太可能發生的事,你就會發現它們。不太可能發生的事,其實發生的不少。
面對投資,最好還是遵循你聽膩的老生常談,「多吃蔬菜、多走樓梯」式的財務健全方案;放棄追尋魔力系統或有金手指的導師,應該把錢放到大而無趣卻收費低廉的指數型基金,然後把它拋諸腦後。
英國統計學家 R. A. Fisher 曾說:即使出現機會是百萬分之一,它還是會出現。無論發生在我們身上時會多令我們吃驚,它出現的頻率既不會多於、也不會少於它該有的出現頻率。
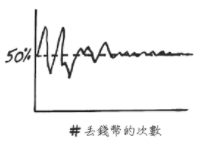
一群人中,至少有兩個人生日相同機率有多高?雖然還要視人數多少而定,但這機率卻出乎意料地高。只要人數在 23 人以上,就有高於 50% 的機率。(Ref: Statistics Hacks)
做些計算或是使用 spreadsheet software,你就能找出各種「自發性」友善賭注。(Ref: Statistics Hacks)