第十四章 魔球 (Flimsy Theories and Rotten Data)
棒球迷信/如果你給我一個D,我就會死(die)/糟糕的出生月份/名人堂的死亡之吻
賽伯計量學 (Sabermetrics):又稱作為棒球統計學,是一項從數據角度分析棒球運動的運動科學。對於棒球活動進行客觀的分析,特別是針對於在棒球比賽時的棒球統計數據做出解釋與評估。這個學門最早源自於比爾·詹姆斯(Bill James)對棒球統計數據所做的一系列分析。
小樣本是否告訴能告訴我們很多資訊,取決於我們如何做抽樣,所做的抽樣是否能代表全部母體,這就是所謂的統計顯著性 (statistical significance)。統計顯著性告訴我們所見是否為事實,而不是偶然發生的。
當要求進行統計分析時,都會問「樣本數要多少?」這是錯誤的提問,但卻是大多數人會問的的一個問題。為了回答這個問題,你應該了解要衡量什麼以及為什麼要衡量。
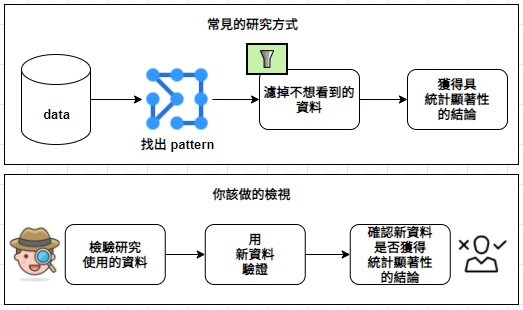
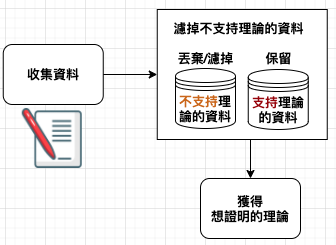
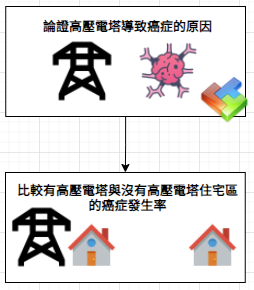
我們當想強調與理論相符的資料,忽略與之矛盾的資料,或者將那些與理論相衝突的資料,錯誤解讀成與之相符的資料。那些本應抱持客觀態度的科學家,卻像個普通人,無法看到局外人所能看到的事情。
在熱切尋找可發表理論的過程中,人們很容易想要微調數據,以便能支持理論。而且,如果統計檢驗給出所預期的答案,人們自然就不想仔細檢驗。如果研究人員在資料搜尋過程搜尋某種模式,然後竄改或刪減不符合此種模式的數據,以便得到具有統計顯著性的結果,你應該對此研究保持警惕。如果統計結論看上去是有問題的,就應檢驗資料。