【Hack #61】Outsmart Superman (智勝超人):閃電可能劈在相同地方兩次,但機率很低。機率的法則能讓我們計算一系列罕見事件連續發生的可能性。

【Hack #62】Demystify Amazing Coincidences (解開神奇巧合之謎):機率的模式會產生一些異常有趣的巧合。本 Hack 將談論如何解讀看似無法置信的巧合。要決定一個巧合是真的很神奇或是單純可預測的,可以使用的一個工具就是數可能的結果數,然後判斷給定的那些結果(巧合)是否不太可能是碰巧發生的,這就是 Hack #45 (預測一大群人中是否有人生日相同) 所採用的做法。

【Hack #63】Sense the Real Randomness of Life (察覺生命真正的隨機性):在你指責賭場經營不當遊戲,或只雇用金髮女郎為由威脅要對你老闆提出法律訴訟前,這裡有個工具可以幫你區分大概是隨機發生的哪些看似不隨機的狀況(看起來隨機 ≠ 真的是隨機),以及實際上真的不是隨機發生的那些看似不隨機的狀況(看起來不隨機 ≠ 真的不隨機)。
【Hack #64】Spot Faked Data (看出偽造的資料):如果你從未想過這點,可能會很自然地假設大多數的隨機資料集中,所有的數字 (digits) 擁有同樣出現的機率。但依據 Benford’s Law,在自然發生的許多種資料中,數字越小,它出現在首位數字 (leading digit) 的情況就會越常見。你可以用這個秘密知識來檢查任何資料集的真實性。此 hack 會描述 Benford’s Law,並示範如何應用它,提供它為何有效的一些直覺解釋,並且提供可套用 Benford’s Law 機時的指導方針。Benford’s Law 說明一堆從實際生活得出的數據中,以1為首位數字的數的出現機率約為總數的三成,接近直覺得出之期望值 1/9 的 3 倍。推廣來說,越大的數,以它為首幾位的數出現的機率就越低。它可用於檢查各種數據是否有造假。但要注意使用條件:1.數據至少 3,000 筆以上。2.不能有人為操控。


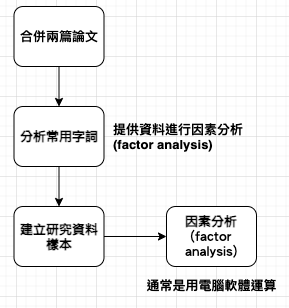
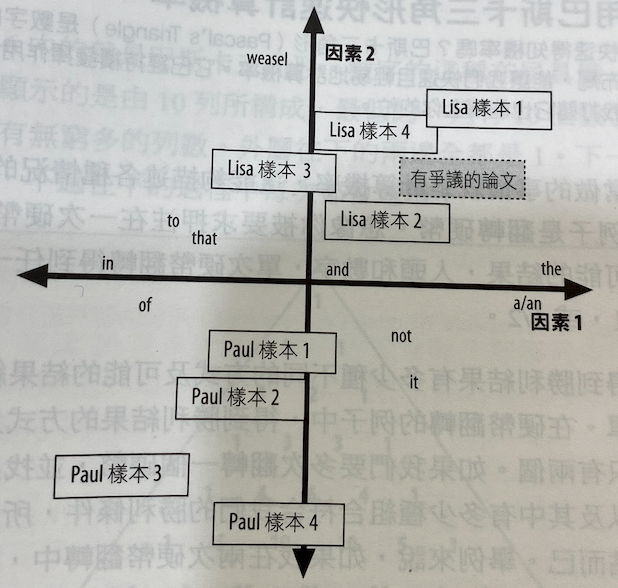
【Hack #65】Give Credit Where Credit Is Due (功勞要歸功於應得之人):文本計量分析 (stylometrics) 是一種統計程序,用來辨識定義一名作者寫作風格的底層維度。其使用因素分析 (factor analysis) 的方法來判斷誰寫了什麼。假設有兩位學生論文互控抄襲,可以做以下分析


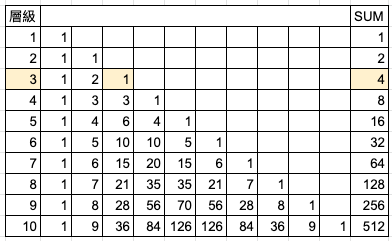
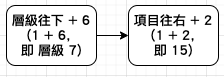
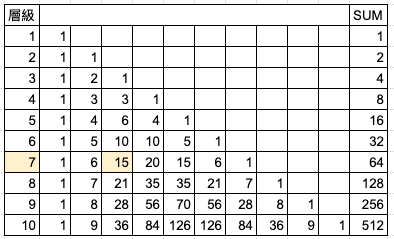
【Hack #66】Play a Tune on Pascal’s Triangle (使用巴斯卡三角形快速計算機率):需要快速得知機率嗎?巴斯卡三角形 (Pascal’s Triangle) 是數字的一種簡單佈局,能讓我們快速且輕易地計算機率。它已經持續發揮作用 300 年了,我打賭它也能幫上你。(https://reurl.cc/e95yyj)




【Hack #67】Control Random Thoughts (控制隨機念頭):我們內在思維漂浮不定的本質,經常被視為好像是在創造一條無法預測的隨機路徑。你可以利用這誤解來猜出你身邊人的想法,方法是增加他們會專注在你希望的任何東西上的機率。
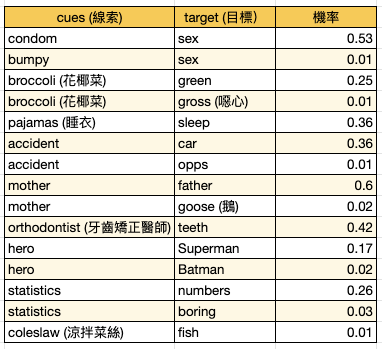
【Hack #68】Search for ESP (找尋超感官直覺, extra-sensory perception):所謂的 ESP 是獨立於傳統五感 (sight, sound, touch, taste, and smell) 以外的感官知覺。雖然大多數的科學家都同意 ESP 實際存在的證據不多,但他們可能是錯的。你或你的朋友或你養的狗可能有 ESP,而現代就是找出它們的最佳時代。

【Hack #69】Cure Conjunctionitus (治癒 Conjunctionitus 思考偏誤):兩個獨立事件同時發生的機率,永遠不會比任一事件獨立發生的機率還高。出乎意料的是,這種嘗試性的真理並不是常被注意到。描述「兩個事件同時發生的機率不可能大於其中任一事件單獨發生的機率」的規則叫做 conjunction rule (合取規則);很多人卻經常認為兩個實踐接連發生的情況比一個事件單獨發生的情況更有可能的這個事實稱為 conjunction fallacy (合取謬誤)。


【Hack #70】Break Codes with Etaoin Shrdlu (以 Etaoin Shrdlu 破解密碼):你永遠都不會知道你何時需要破解秘密訊息,不管那是你的同事 James Bond 攔截到的,或是你的醫師撰寫處方時潦草寫下的。這裡是你會需要的所有統計技巧,探員 003.14159。


【Hack #71】Discover a New Species (發現新物種):雖然每天都有某個物種的生物在滅絕,偶爾也會有之前不知道的新物種被發現。令人意外的是,統計工具而非生物工具,可以做到這點。假設我們要找出澳洲的短耳負鼠 (short-eared possum) 中,是否有新的物種
【Hack #72】Feel Connected (感受關聯性):「六度分隔 (six degrees of separation)」的概念不僅是社群的新時代隱喻或涉及演員 Kevin Bacon 的派對遊戲。如果你想要實際測試「我們都認識某個認識所有其他人的人」這個概念,就找出你與每個人的連結有多接近吧。


【Hack #73】Learn to Ride a Votercycle (學習駕馭投票循環):雖然自由的選舉看似制定政策和選擇官員最公平且明智的一種系統,統計學家有時還是會擔心政治科學家叫做「投票循環 (vote cycling)」的一種矛盾,它可能會導致少數獲勝。
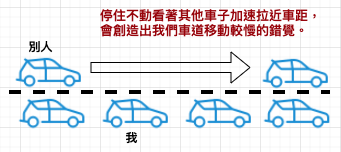
【Hack #74】 Live Life in the Fast Lane (You’re Already In) (快車道上的生活):應用機率法則、對人性的知識。以及高速公路駕駛的一些事實,你就能做出明智的切換車道選擇。以統計學為基礎進行電腦模擬的研究指出,即使事實上移動的速度相同,駕駛人通常會認為另一個車道移動得比他們的車道還快。調查研究所發現的這個錯覺,會讓大多數駕駛人試著變換車道。
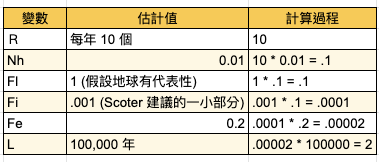
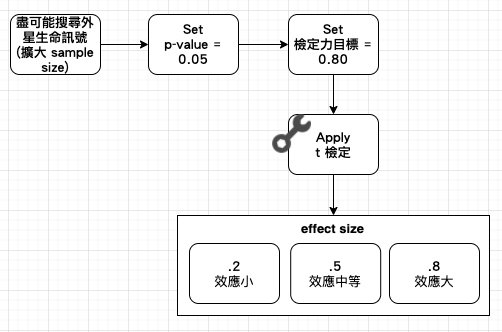
【Hack #75】Seek Out New Life and New Civilizations (搜尋新生命體與新興文明):探查外星生命體的搜尋活動持續且順利進行中,你可以使用統計的抽樣發法和機率規則來縮小搜尋範圍。