第一章 模式、模式、模式 (Patterns, Patterns, Patterns)
混雜效應/選擇性報告與謊言/易受欺騙的本性/無論文,不生存/統計顯著性膜拜
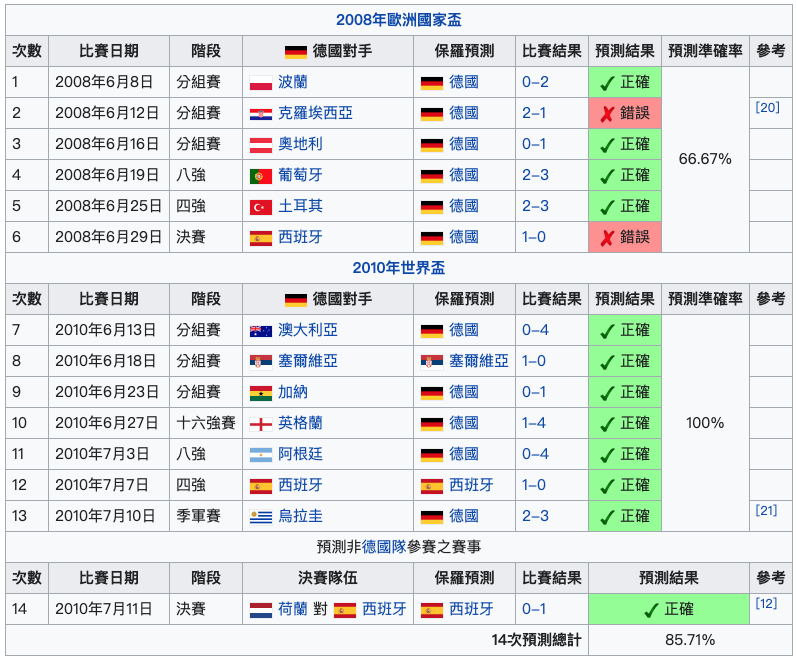
【干擾效應】章魚保羅 (2008年1月26日-2010年10月25日) 是德國奧伯豪森 (Oberhausen) 一個水族館的一隻普通章魚,據稱這隻章魚能準確預測德國國家足球隊的比賽結果,因而有「章魚哥」、「保羅哥」之稱。章魚是色盲、能辨識明暗度、喜歡橫向形狀,這就能解釋其會選擇德國、西班牙、塞爾維亞等由三塊鮮豔的水平條文組成的國旗。國旗只是一個干擾因素,保羅不是挑選最佳的足球隊,而是牠喜歡的國旗。無所不知的保羅,只是一隻缺乏智商的章魚。
對於保羅的成功,另一種解釋是,許多人嘗試這種愚蠢的寵物預測把戲,用寵物來預測體育、彩券、股票領域。在 1000 個拋硬幣的人當中,一定會有一個人連續拋出 10 次正面;相同的道理,在那些嘗試寵物把戲的人當中,一定有一些人會成功。你覺得誰會獲得報導?是選獲勝隊伍的章魚?還是預測失敗的鴕鳥?這就是「選擇性報告」與「謊言」。
人類容易受騙,其實是因為老祖先遺留下的 DNA:我們很容易受到模式以及解釋模式的理論所迷惑;常緊盯支持這些理論的證據及忽視與之矛盾的證據。我們總是渴望不確定的世界變得更確定,渴望控制無法控制的事物,渴望預測無法預測的事物。
Examples | 說明 |
🎲 賭桌 | 在雙骰賭桌上不斷搖出七點,你認為自己會繼續連勝,因為你希望如此;當你不斷骰出兩點,你認為自己即將轉運,不會一直這麼衰,因為你希望如此。其實,骰子沒有記憶,也不關心未來,每次擲骰都是獨立事件。 |
📈 購買熱門股票 | 如果其他人購買這檔股票都賺錢,那麼我們跟著買也一定會賺錢。 |
🧦 幸運襪 | ⛹️♂️ 把上一場獲勝原因歸功給襪子,運動員繼續穿著上次沒洗過的獲勝幸運襪,希望複製上一場的好表現。 |
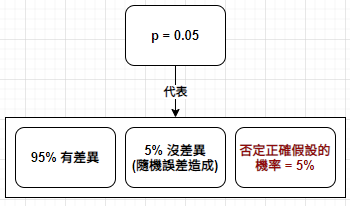
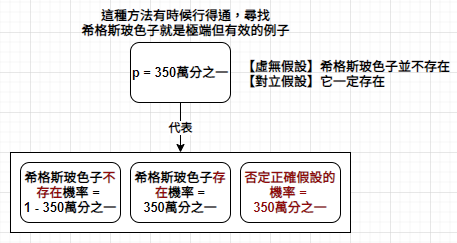
在大多數研究人員看來,< 0.05 的機率具有「統計顯著性」(statistical significance)。如果數據中的模式憑運氣出現的可能性不到 1/20,這種模式就被視為具有統計說服力。例如,章魚哥的預測具有統計顯著性,憑運氣獲勝的可能性 < 1% (116384),但這是代表章魚哥很會預測嗎?
提升檢定力 (Power Up):統計分析經常需要判斷在某個樣本中觀察到的一個特定的值是否是碰巧出現的,此過程稱為顯著性檢定 (test of significance)。顯著性檢定會產生機率值 (p-value, probability value),如果 p-value 很小,說明原假設情況的發生的概率很小,而如果出現了,根據小概率原理 (small probability principle),我們就有理由拒絕原假設,p-value 越小,我們拒絕 H0 的理由越充分。在大家習慣採用 0.05 當作一個臨界,當研究的 p 值小於這個臨界值的時候就宣稱研究結果達到統計顯著,也就是說大家普遍同意接受 5%犯錯的可能性。研究與統計學者於實驗結果常使用下列說法:
統計研究常見陷阱
統計研究常見陷阱 | 解法 |
從樣本自以為找到母體某項特性,但是只存在於樣本中 | 以對母體具有代表性的方式進行抽樣 |
在樣本找不到任何特性,母體卻確實存在 | 增強統計檢定力 (power) |
檢定力並非找到顯著結果 (significant result) 的機率,它是某種關係「真的存在」時,找到該種關係的機率。檢定力的公式包含三個組成部分:
檢定力的公式包含三個組成部分 |
① 樣本大小 (sample size) ② 要達到 (小於) 預先決定的顯著性水平 (p-value) ③ 效應大小 (effect size, 母體中該項關係的強度) |

|
如何解讀研究發現
解讀研究發現 | 說明 | 例子 |
統計顯著性 (statistically significant) | 回答這個關係可能出現在母體嗎? | 服用 aspirin 的患者,心臟病發的可能性是服用安慰劑哪組的 50%,代表有統計顯著性 |
效應大小 (effect size) | 回答這個關係有多大? | 運用比例式比較 (proportional comparison) 的公式,此研究的 effect size = .06 個標準差,or .06 的 d,代表 aspirin 與心臟病的關係真實存在,但是沒有很強烈 |
顯著性 (significance) 告訴你的是此關聯可能存在於母體中,若是效應很小,使得沒人對它有興趣。 |
設計 5% 作為顯著性水準的門檻是長期經驗的結果,也是社會科學和生醫科學常用的準則。如果 p=5%,即是指 100 次相同方法(但抽取的樣本不同)統計的結果,有 95 次會掉在信賴區間內,有 5 次會在信賴區間外。可是因為它太常用,導致一種錯覺,以為達到「顯著性水準」如 p 值 < 5%,就算是「驗證」了假設;如 > 5%,就算是否證了假設。例如,如果在藥物療物檢驗上,一次檢驗的結果,沒有達到 < 5% 的顯著性水準,就結論說該藥物是無效的。換言之,把 p 值當成一種「確定性」的指標,那就在科學推論上犯了很大的錯誤。統計顯著性是一種「偽確定性」,p值的「內具不確定性」必須被牢記。(Ref: https://reurl.cc/NXOZYq )
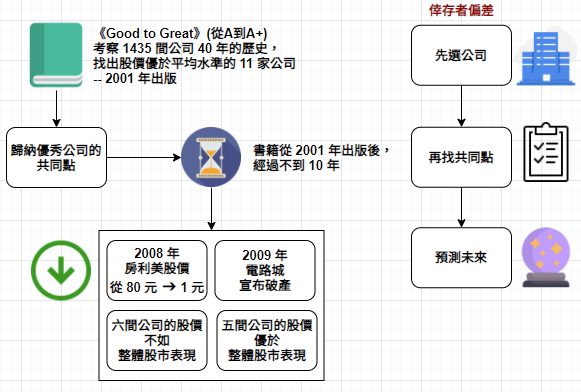
如何判斷正確理論或胡謅?有兩種良方:常識與新數據。
如何判斷胡謅 | 說明 |
用常識判斷 | 若某種理論聽起來很可笑,在看到壓倒性的證據前,絕不輕易相信。即使看到壓倒性的證據,仍保持懷疑態度。不尋常的說法需要不尋常的證據。遺憾的是,在這個年代,常識是個稀缺品,許多誠實的研究人員用嚴肅語氣提出愚蠢研究。 |
用新數據驗證 | 當你收集資料、編造理論時,用同份資料進行檢驗是不明智的。既然你的理論是從這些資料得出結論的,怎麼檢驗都會符合結論,應使用不受資料收集污染的新資料來做驗證。 |
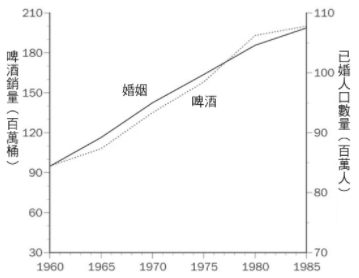
我們往往會尋找重複出現的模式 (patterns),並且相信我們觀察到的模式是有意義的。不要天真的以為重複出現的模式就是證據,我們需要一個符合邏輯、具有說服力的解釋,並且用新資料檢驗這種解釋。重複出現的模式 (patterns)有:
重複出現的模式 (patterns) |
① Stephen Curry 連續命中四顆三分球,很有可能第五次出手也會命中。 |
② 當 NFC 冠軍隊贏得超級盃,股市一定會上漲,故要看完比賽再去投資。 |
③ 一個國家在高負債時出現經濟衰退,這說明政府的債務導致經濟衰退。 |