網路 (Networking) — 我們如何互通聲息
人類互通訊息的基礎是通訊協定 (protocol),也就是程序和預期的共通慣例,例如,握手、打招呼和禮儀、禮貌、以及各種社會規範,機器間的聯繫也不例外。從電報到簡訊,通訊科技雖然提供人與人之間溝通的新管道,但人與人之間仍有溝通障礙。Internet 問世後,電腦不僅是溝通管道,也是負責交談的聯絡點,因此它們必須負責解決本身的溝通問題。機器間的這類問題 (以及解決方案),跟人與人之間的問題相仿,很快變成我們借鏡的對象。
拜占庭將軍 (Byzantine Generals Problem) 問題

工作量證明 PoW (Proof of Work):(Ref: https://reurl.cc/e9yqoW, https://reurl.cc/nnvkMd )
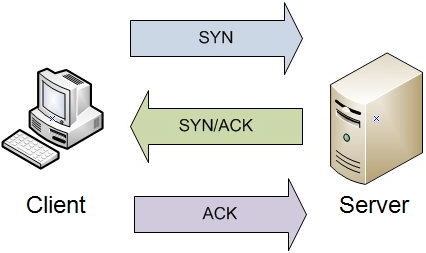
TCP 三向交握 (Three-way Handshake) (Ref: https://reurl.cc/WENprD )
網路傳輸並不保證送達,面對不可靠的人或電腦,我們所面臨的問題
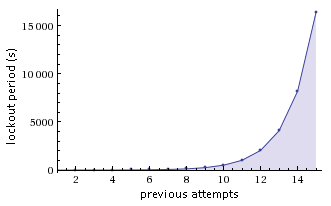
指數退讓法 (Exponential backoff) 在網路安全也扮演要角,有人藉著連續輸入密碼試圖 login 失敗時,它會以指數方式延長鎖定時間,防止 hacker 利用「字典式攻擊」入侵帳號,不斷輸入可能的密碼,直到成功為止。
TCP 壅塞控制 (congestion control) 的核心,稱為加法遞增乘法遞減演算法 (AIMD, additive-increase/multiplicative-decrease)。在 AIMD 中,一批封包完整接收後,不會讓傳送封包數加倍,而只會 +1,而發生封包遺失時,則會使傳輸率降一半。實質上, AIMD 的策略就是:「多一點、多一點、多一點、阿太多趕快減少、多一點、多一點 …。」它產生的頻寬變化圖形稱為 TCP 鋸齒圖 (TCP sawtooth),先逐步緩升,穿插幾次陡然下降。保守主義在此非常重要,所有使用者的速度都不能超過網路過載的速度,如此才能維持網路穩定。同樣地,加法遞增有助於穩定整體狀況,防止出現劇烈過載和復原循環。

(Ref: https://reurl.cc/qmnDxR )
許多動物的覓食行為類似 TCP 流量控制與特殊的鋸齒曲線。追逐人類食物碎屑的松鼠與鴿子,每次都會往前走一步,偶爾退後好幾步,然後再往前走一步。
TCP 鋸齒圖 (TCP sawtooth) 告訴我們,在無法預料與不斷變化的環境中,要充分運用全部資源,最好與唯一的方法,就是把狀況推出到出現錯誤。最重要是確定錯誤、反應迅速,而且很快就能恢復。在 AIMD 演算法中,沒有中斷的連線會加速到中斷為止,接著減速一半,又立刻加速。在 TCP 中,沒有單向傳輸,一旦沒有持續的回饋,發送者會立刻減緩發送速度。
彼得理論 (Peter Principal) 提到「所有員工通常都會升到無法勝任的職」,套用 AIMD 演算法,假設有間公司的員工不是每年晉升一級,就是降階若干級,如此就不會有人抱怨一直沒獲得升遷,也不會有人憂心長期負擔過重。
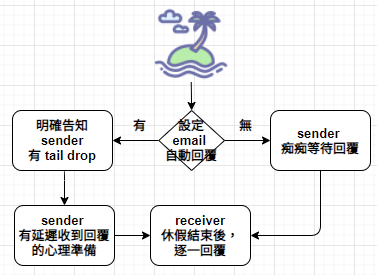
buffer / queue 的概念:當你與另一位客戶幾乎同時走進一間甜甜圈店,收銀員由於一時忙不過來,於是請你們其中一個人排隊稍後。如此一來,可以確保收銀員不會過勞,請客戶排隊可確保店裡的平均處理量可達最大處理量,這是好事。但這種優秀的資源運用方式,必須付出「延遲代價」。當排隊人數越多,隊伍越長,等待時間就越久;若店家在目前隊伍末端,立個標示牌表示本日 sold out,這對顧客與店家可謂皆大歡喜,店家表示已達本日最大產量,顧客也不用浪費時間排隊,可以去買其他東西。出於策略刻意讓球落地,是在負擔過大時完成工作的重要方法。
當緩衝區已滿,通常會出現 tail drop 現象,代表在此之後到達的封包都會直接拒絕並刪除。隨著科技進步,記憶體價格下跌,處處充滿了大型緩衝區的網路設備,這對基於遺失 (lost-based) 的壅塞控制演算法造成巨大的問題。大型的緩衝區,使封包不易被丟棄,而是在佇列中緩慢地等待,TCP 傳送端 並不知道 壅塞的發生,仍持續成長傳輸速率,使網路產生高延遲、吞吐量下降的惡性循環,這就是惡名昭彰的 — 緩衝區膨脹 (bufferbloat)。(Ref: https://reurl.cc/v5paRL, https://reurl.cc/xgpa7V )


運用「Tail drop 概念」於 e-mail 自動回覆功能
許多公司強調的「高速網際網路」,指的是高頻寬,而非低延遲;網路工程師早該將「低延遲」視為最優先的問題。我們需要更多協和式客機 (Concorde),而非更大台的波音。例如,對線上遊戲玩家而言,即使 50ms 的延遲,都可能影響到他幹掉別人,還是別人幹掉他。