在這個假新聞盛行的時代,很難知道能相信誰。雖然很多人不相信,但是大多數的主流媒體仍維持著以事實為根據。然而,許多媒體所報導的「事實」卻仍有不同,問題就在於觀點的偏頗。例如,2017 年 Donald Trump 的稅改法案,不同的新聞台記者,給予不同的報導內容
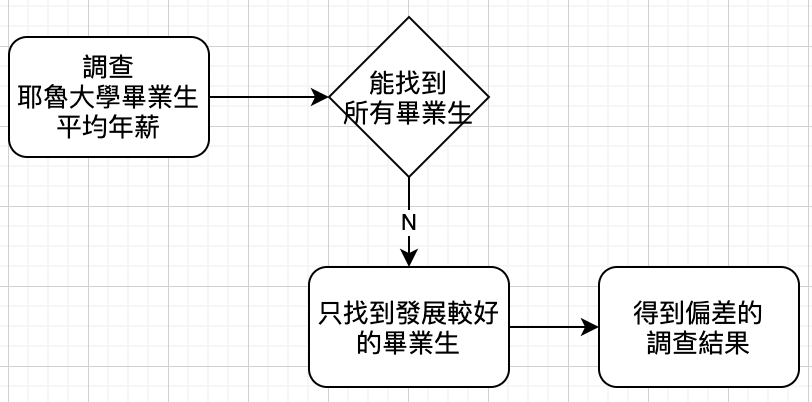
用刻意「遺漏」的手法,忽略其他數據,就能創造出完全扭曲的報導。有時候,研究本身不可靠,可能是樣本數太少、樣本不具代表性或帶有偏見,用了誘導性提問,又或選擇性報告 (selective reporting),都可能導致統計數據不可靠。
刻意將統計數據從脈絡中撥離,也是常見的愚弄手法。例如,某個疾病的案例增加 300%,但並未告訴你是從 1 名增加為 4 名,或是從 50 萬名變成 200 萬名,情境脈絡就是有這麼大的影響力。
生日問題 (birthday problem):一群人中,至少有兩個人生日相同機率有多高?雖然還要視人數多少而定,但這機率卻出乎意料地高。只要人數在 23 人以上,就有高於 50% 的機率。《Statistics Hacks》
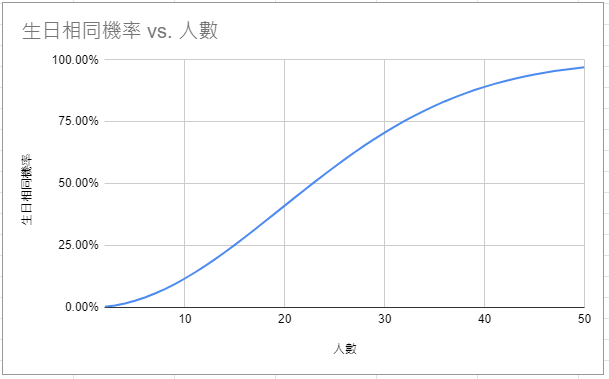
下次你去酒吧,可以用上述生日問題,來跟你朋友打賭,看能否找到兩個生日在同一天的人。在某場與朋友的聚會,我觀察當時共有 40 個顧客,經過上述的計算,我的勝率高達 89.12%,最終順利喝到免費啤酒。
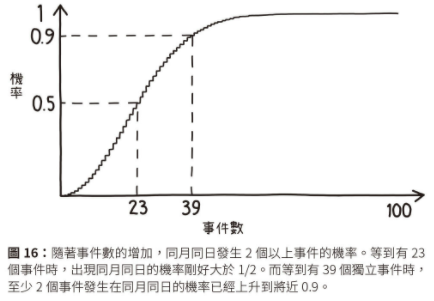
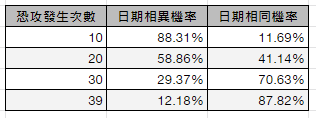
恐攻新聞:2017/5/22 曼徹斯特發生恐攻,新聞報導這是因為 2013/5/22 也發生恐攻,這是經過精心策畫的恐攻計畫。
Small sample fluctuation:廣告常會用百分比來展現使用前後效果,因為其樣本數很小,所以他會告訴你使用後 82% 有效,但是不會告訴你 樣本只有 34 個,其中 34 人中,有 28 個人有效,以免被發現樣本數少的令人尷尬。
發表偏差 (publication bias) 或稱為抽屜問題 (file drawer problem):是指使用統計顯著性作為發表與否的門檻,可能會大幅扭曲某些假設獲得的證據。投資人跟科學家一樣,只看到因巧合而成功的那次就信以為真,但是卻忽視為數眾多的失敗案例 (ex. 沒有通過檢定的案例就收進抽屜)。《how Not To Be Wrong:The Power of Mathematical Thinking》
確認偏誤 (Confirmation bias) :是心理學上的一種現象,簡單的說,就是人們都會傾向於尋找能支持自己理論或假設的證據,忽略不能支持自己理論或假設的證據。這種選擇性的擷取資訊來強化自己理論或假設的現象,幾乎在每個人身上都看得到,但能意識到的人卻很稀少,更不要說能去盡力避免了。《Antifragile: Things That Gain from Disorder》
小樣本是否告訴能告訴我們很多資訊,取決於我們如何做抽樣,所做的抽樣是否能代表全部母體,這就是所謂的統計顯著性 (statistical significance)。統計顯著性告訴我們所見是否為事實,而不是偶然發生的。《Standard Deviations: Flawed Assumptions, Tortured Data, and Other Ways to Lie with Statistics》
政治民調從業人員發現,必須更了解統計知識,才能得到準確結果;但政客卻發現,如果能更理解統計上的操控、挪用與舞弊,就能做盡壞事卻不受懲罰。
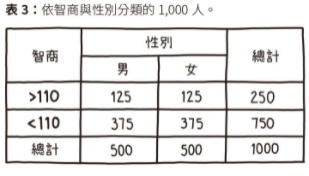
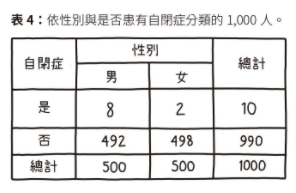
👮 🚶🏿♂️ 當「黑人的命也是命」(Black Lives Matter)」活動風起雲湧時,許多人主張警察遇到黑人嫌犯會直接開槍,而非逮捕。但是,根據統計數據顯示,美國黑人面對最大的危險,其實是其他黑人。
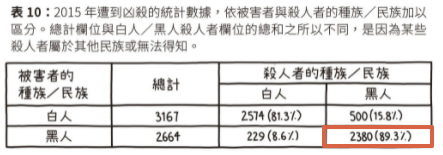
絕對風險 vs 相對風險

如果是一篇刻意危言聳聽的文章,你就會發現文章裡不會提到絕對風險。絕對風險通常只會是兩個小數字:一個是罹患該疾病或使用某療法的族群,另一個代表的是其他人口。如果你想找出標題背後的真相,可以做後續追蹤調查,看有沒有媒體提供絕對數據。
絕對風險 vs. 相對風險 (https://reurl.cc/yeqrDy)
決策者會因資訊採採正面或反面的說法,而導致決策者做出南轅北轍的決定,這是因為你只用 System 1 來思考做決策,完全沒用到 System 2。《Thinking, Fast and Slow》

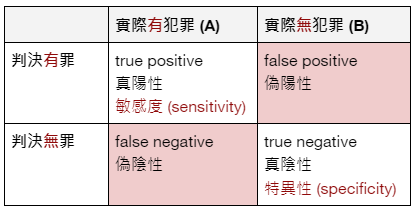
Fourfold pattern 《Thinking, Fast and Slow》
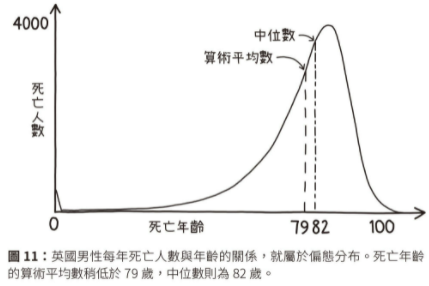
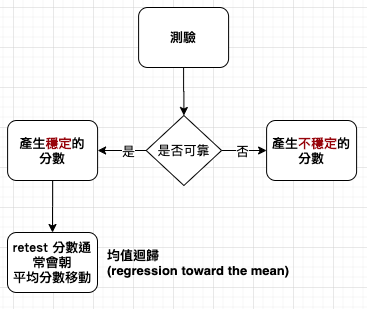
只要測試結果與機率有關,就會受到回歸均值 (regression to the mean) 的影響。例如,真實的考試中,成績當然和熟練程度有關,但也帶點運氣的成分,要看你的事前複習是否剛好猜到考題。運氣成分在選擇題考試特別明顯,就算學生完全沒有相關知識,也能猜對答案。
回歸是雙向的,因為它僅僅反映了「隨機波動」。身高很高的父母,通常子女會矮一點;身高很高的子女,通常父母會矮一些。這種現象不限於身高,回歸均值存在於無法靠觀測準確反映的任何遺傳特性中,包含身高、體重、智力、足部尺碼、頭髮密度等。異常的父母通常擁有不太正常的子女,異常的孩子通常擁有不太異常的父母。《Standard Deviations: Flawed Assumptions, Tortured Data, and Other Ways to Lie with Statistics》
當學術能力和運動能力等特點得不到完美測量時,觀測到的表現差異會誇大實際能力差異。表現最優秀的人與平均水準的距離,很可能不像看上去那樣遙遠,表現最糟的人也是如此。因此,他們隨後表現將回歸均值。回歸均值也不是意味能力像均值收斂、大家很快會有平均水準,它只意味著,極端表現在經歷好運和壞運的群體間輪換。回歸均值也不代表成功和不成功的公司會走向令人沮喪的平庸。《Standard Deviations: Flawed Assumptions, Tortured Data, and Other Ways to Lie with Statistics》
如果你不喜歡在某個重要的高風險考試上得到的分數,你該再考一次嗎?《Standard Deviations: Flawed Assumptions, Tortured Data, and Other Ways to Lie with Statistics》
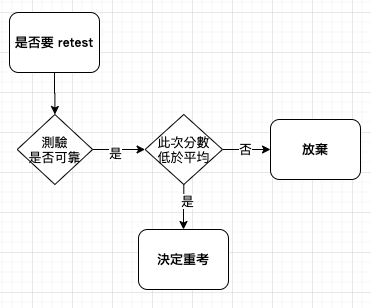
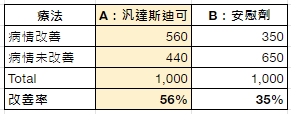
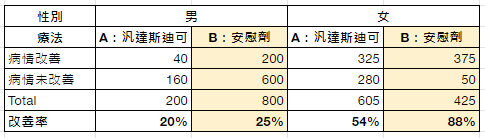
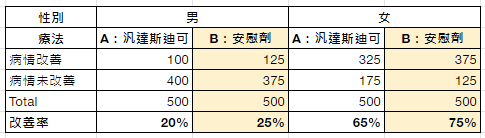
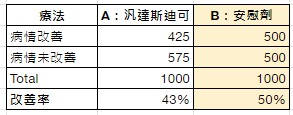
雙盲測試 (double-blind test) 是公認的臨床試驗的黃金標準做法,若採用雙盲隨機對照試驗,對照組與治療組兩個病況改善的差異,就可以歸因於療法本身,排除回歸均值效應、安慰劑效應 (placebo effect)。
常見臨床試驗法 (Ref: https://reurl.cc/kVWmDL )
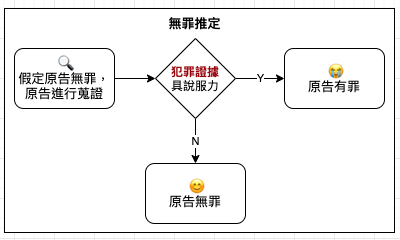
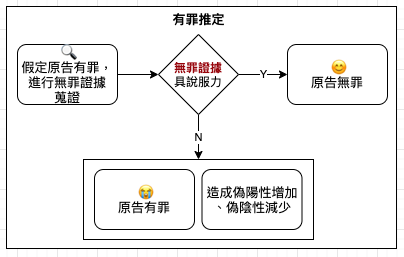
判斷統計數否遭操弄的檢查表
只要發現某個統計數據沒頭沒腦的出現,就跟自問:①「比較對象是什麼?」、②「動機是什麼?」及 ③「這是完整事實嗎?」只要找出這三個問題的答案,已經能讓你在判斷數據是否真實的道路上邁進一大步。光是找到這三個問題的答案,就足以說明許多事。
Darrell Huff 在 《How to Lie with Statistics》(別讓統計數字騙了你) 提到:「統計雖然擁有數學的基礎,但統計學的藝術成分並不少於科學成分。」到頭來,我們有多麼相信自己所碰上的統計數據,取決於那位藝術家所畫出的圖像有多完整。
《How to Lie with Statistics》提出的例子 https://reurl.cc/gzd3V4