⛅ 當資料收集越詳細,電腦運算能力越強,確實可以讓預測結果更好。美國數學與氣象學家 Edward Lorenz:「不管我們收集多少資料,對於能預測多久以後的天氣,仍有難以跨越的極限,我認為我們頂多只能預測兩週內的天氣。」目前全世界氣象學家共同努力的結果,仍無法打破 Lorenz 的估計。
對於天氣,我們有非常優良的數學模型,只要增加數據量,至少在短期預報可以表現很好,儘管我們知道天氣系統內在的混沌性,最終會破壞預報準確性。但對於人類行為,我們連模型都沒有,也可能永遠都不會有,這使預測人類行為難上加難,比預測天氣還難。
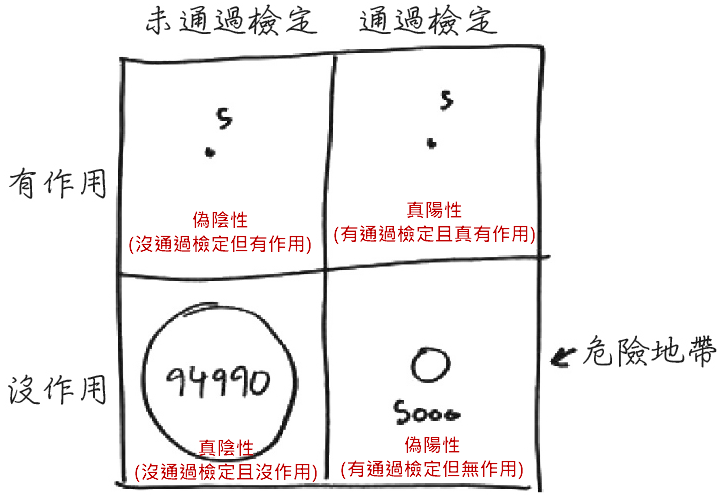
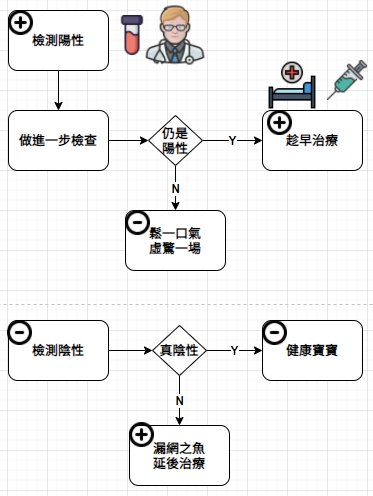
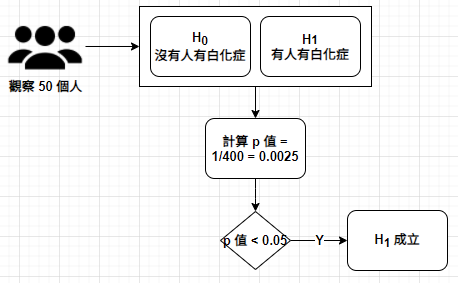
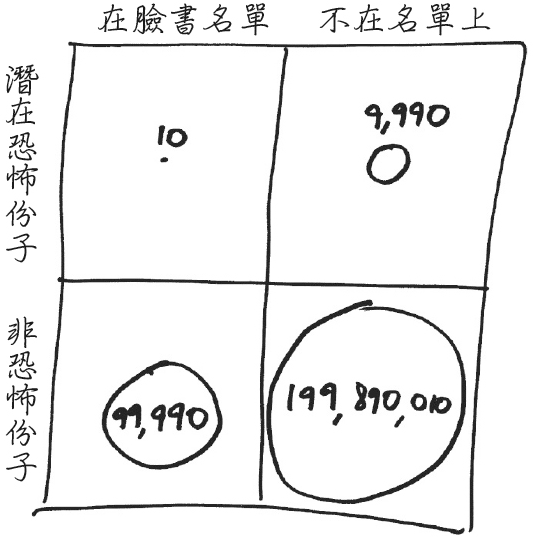
Facebook 使用演算法算出可能的恐怖份子,真的是是恐怖份子的機率有多少?

貝氏定理 (Bayes' Theorem)
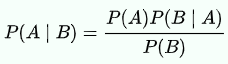


如果你想要成為具有正確直覺的貝氏統計學家,若你想自然地做出正確預測,不需思考應採用哪個預測法則,就必須好好保護你的事前分布,你該做的反而是違反直覺地少看新聞。
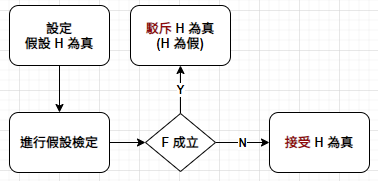
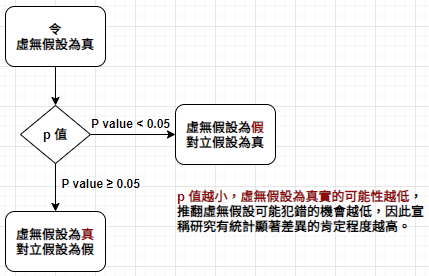
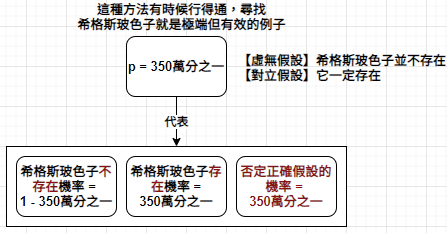
Sherlock Holmes 曾說:我有一條座右銘,當你把不可能都排除後,不管剩下來的可能性有多低,必然是真相,除非真相是你從沒想過的假設。