有句老話說,樂透是「笨人繳的稅」,是政府犧牲那些遭誤導去買樂透所獲取的收入。如果你把樂透看成稅收,你就知道為什麼美國各州的財政局都喜歡樂透。還有別的稅目能讓人在便利商店大排長龍去繳嗎?
期望值很適合用來標定物件的恰當價格,例如在真正價值並不確定的賭狗場合,如果用 $12 下注,長期下來可能會輸錢;反過來說,如果改用 $8 下注,或許應該盡量長期下注。
Laplace’s Law (拉普拉斯定律) 計算期望值:假設買 n 張彩券有 w 張中獎,期望值= w+1n+2。想算出公車遲到機率嗎?你參加的壘球隊的贏球機率?只要算一下過往發生次數 + 1,再除以機會數 + 2 即可。拉普拉斯定律的優點在於,無論只有一個資料點或是有數百萬個資料點,它一樣有效。例如,地球上已經連續看見太陽約 1.6 億次,明天太陽還是會升起的機率與 100% 無差別。
年金的定價與投保年齡有關,這也是期望值的概念。透過新生與死亡的統計,就能估計每位年金購買者的存活機率,計算出年金的期望值:「購買年金的人應依他的存活機率,付出相對應價格;這需每年計算一次,最後把那些年度價值加總後,就是購買者終身年金的價值。」換句話說,老爺爺未來日子較短,所以年金購買價格會比孫子便宜。
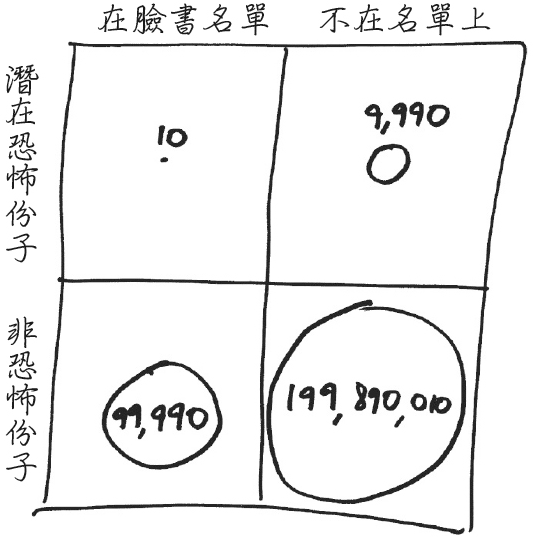
期望值和機率的運作概念仰賴大數法則,數量足夠多的情況下比較有參考價值。例如,投擲一枚公正的硬幣出現人頭的機率二分之一,指的是投擲足夠多次後人頭出現的頻率約佔全部的二分之一,足夠多可能只要幾千或者甚至幾百就能夠觀察出來,而中樂透頭獎的足夠多次可能就得進行高達以億兆萬計的等級。(Ref: https://reurl.cc/dVE74q)
平均來說,玩樂透的人花出去的肯定比贏回來的人多,所以樂透的期望值必然是負的。當頭獎獎金極高、你又想投注且不想跟別人平分時,有幾個策略:
對於政府來說,彩券賣得越多,國庫進帳更多。所以,政府只關注有多少人買彩券,不管誰贏錢、只管抽稅,因為贏走的錢也是買家們貢獻的錢,不是政府的錢。樂透得主賺的不是政府的錢,是其他買家的錢,投注集團沒有打敗莊家,他們自己就是莊家。
大樂透期望值計算

賭場經營是一門生意而不是在賭博:大量客人平均贏的錢會很接近期望值,而莊家老早就算好了期望值,並且知道長期下來,這門生意會賺多少錢。
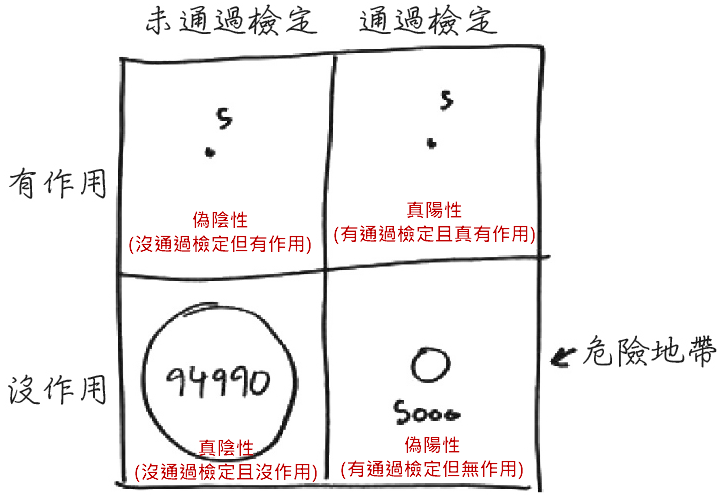
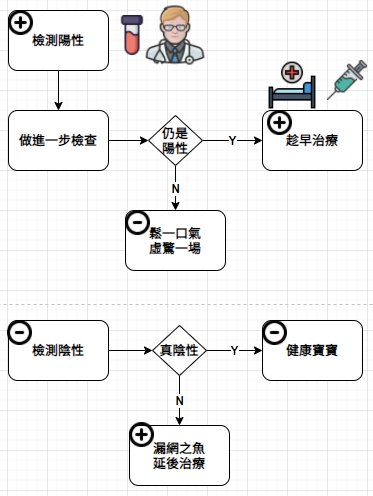
人壽保險公司的運作很像賭場─賭被保險人會不會死亡:依據死亡率,預測出必須給付的理賠金期望值,然後訂出保費來保障其公司之利潤。