快取 (Caching) - 忘掉就算啦!
書桌的空間有限,cache 也是如此。當 cache 裝滿時,就需騰出空間後,才能放新的資料。騰出空間的程序稱為快取替換 (cache replacement) 或快取剃除 (cache eviction)。cache 的容量比主記憶體的容量小很多,資料不可能永遠放在 cache 裡,故系統會使用演算法逐步覆蓋 cache 內容,此演算法稱為替換策略 (replacement strategy) 或剃除策略 (eviction strategy)。
Bélády 於 1965 年發表的快取演算法論文,成為被引用次數最多的電腦科學研究長達 15 年。論文提到,cache 的目標,是盡量減少在 cache 中找不到所需的資料,以致於必須轉至速度較慢的記憶體尋找的狀況,這類狀況稱為巡頁丟失 (page fault) 或快取未中 (cache miss)。cache 的最佳策略是,在 cache 快滿時,剃除最久之後才會再次需要用到的資料。
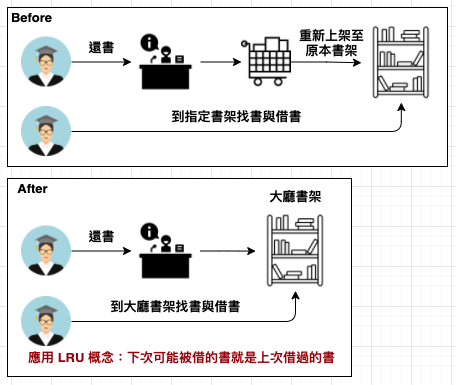
在電腦科學家進行的大多數測試中,LRU 演算法表現得非常優異。這帶出一個應用至圖書館:把圖書館內外翻轉,把新進書籍放後面,讓想看的讀者自己去找;最近剛歸還的則放在大廳書櫃,讓學生跳過上架程序先看到這些剛歸還的書,圖書館員不必進入書庫放置圖書,學生也不用進入書庫再拿出來,這就是 cache 的原始用意。
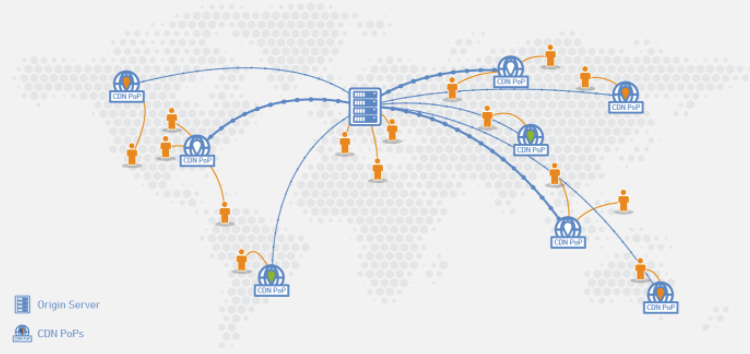
CDN (Content Delivery Network,內容傳遞網路) 就是一種 cache 技術。 CDN 會將快取的內容儲存在使用者附近的邊緣伺服器上的存在點 (POP) 位置中,以將延遲降至最低。
Amazon 也將 LRU cache 概念應用在物流管理,並取得專利。此專利名稱為「預測包裹寄送」,讓 Amazon 在消費者下單前,將商品先寄送到消費者該區的臨時倉庫,此概念與 CDN 相仿。當消費者真的下單時,商品距離消費者已經很近,將交貨時間最小化。

LRU 應用於生活
在文件收納,若我們遵照 LRU 原理,每次都把抽出來的文件放回檔案列表最前面 (move-to-front),那麼搜尋所花的時間,絕對不會超過我們所預知的兩倍,其他演算法都無法保證這點。LRU 不僅是最有效率,而且是最佳方法。
LRU 雖然是最有效率而且最佳方法,這不代表我們必須放棄分類。如果想把物品弄得華麗一些,同時加快搜尋速度,你可在不同的檔案類別貼色彩色標籤。如此一來,若你要找的是帳戶類的資料,就可以把線性搜尋限制在這類的檔案,這個類別的檔案可依據「移至前端」(move-to-front) 法則排序。

當我們面對一箱文件時,可以將其旋轉 90 度,從一箱檔案變成一疊檔案,如此一來搜尋檔案時自然會從上至下,每次抽出文件後要放回去,自然就會放最上面。我們也可強制電腦將電腦文件顯示為一疊,電腦預設以名稱 A 到 Z 排序,但從 LRU 強大的功效看來,我們應更改原始設定,修改為「最近開啟」,這樣我們要修改的檔案大多會集中在最上方。
在書桌上一大疊文件不但不是雜亂象徵,還是目前已知最精良、效率最佳的資料結構,沒必要因此感到罪惡感。在別人眼裡看來或許凌亂、欠缺條理,其實它自有一套條理。由於我們無法預知未來,所以把用過的東西放在最上面是最好的方法,刻意不排序往往比花時間排序更有效率,我們不需整理的理由不是懶,而是已經整理好了。
Cache 特別強調時間,人腦的記憶無可避免必須進行取捨,而且結果一定是零和。我們無法把所有圖書館的書都放到書架上、把所有商品都放上商店的商品陳列架上、把所有論文都放在整疊文件的最上方、把所有的事實/臉孔/姓名都放在頭腦的最前端。我們常認為人隨著年紀人隨著年紀增長而變得健忘是「認知功能衰退」,然而如果記憶非得進行取捨,而且大腦已經非常適應周遭世界,那麼或許就不是認知功能衰退。
當電腦記憶體容量越大,搜尋與取出所需資料的時間就越長。人腦也是如此,當年紀越大,需要處理的記憶容量就越大,每天要解決的運算問題就越艱辛。經研究,單單只是懂更多,就會影響辨識單字、人名甚至字母的能力,無論採用的整理方法多優異,只要必須搜尋的資料量增加,花費的時間就會拉長。
Cache 讓我們理解大腦的運作,我們常說到的「恍神」其實是快取未中 (cache miss)。檢索資料時的延遲機率變高,代表我們應把最需要的資料放在最前端,藉此提高檢索效率。當我們漸漸老化,就會開始出現延遲現象,也不用過度擔心,這也代表我們經驗豐富程度。檢索時花費的力氣代表我們知道多少東西,很少出現檢索延遲代表我們整理得很好,經常把最重要的東西放手邊,隨時取用。