我們目前使用的是「十進位制位值系統」(decimal place value system),所謂的「位值」(place value) 是指,不同位置的數字代表不同的數值;而「十進位」是指,同一個數字放在相鄰位置,代表的數值會比隔壁大或小十倍。不同位置間的相乘係數稱為進位基數,在十進位就是 10。
🖐️🖐️人類會廣泛採用十進位,而非其他進位,理由很簡單,我們要計數時,就是用十根手指來計數。
古羅馬系統的數字系統較為原始,共有七個符號如下表。古羅馬人意識到自己的數字系統效率低落,因此規定數字永遠要由左而右寫,從最大小到最小,這樣就能方便做數字加總。例如,MMXV = 1000 + 1000 + 10 + 5 = 2015;1888 年完成的波士頓公共圖書館,就刻著 MDCCCLXXXVIII ( = 1000 + 500 +100 +100 +100 + 50 + 10 +10 +10 + 5 + 1 +1 +1,足足有 13 個字元,是上個千禧世代最長的羅馬數字。
雖然羅馬數字的使用歷史悠久,佔有優勢,但這套符號系統過於複雜,不利於高等數學的發展,因而從未通行世界。事實上,羅馬帝國的一項著名事蹟,就是沒有傑出的數學家,對數學研究沒有什麼貢獻。
六十進制是以 60 為底數的進位制,源於公元前三千年至公元前兩千年的蘇美人,後傳至巴比倫,流傳至今仍用作紀錄時間、角度和地理座標。(https://reurl.cc/bnQAby)
我的兩個小孩讓我學到一項痛苦的教訓,分東西的時候一定要公平。我敢打包票,他們寧願兩個人都只有一個糖果,也不希望自己有 5 個、對方有 6 個。 如果你是以兒童為重點的產品製造商,以 12 個為一組的賣法就能讓客群最大化、也最不容易惹惱客戶,無論是要應付 1 、 2 、 3 、 4 、 6 、 12 個孩子的家庭都沒問題。
一如蘇美人用的 60 進位,十二進位優於十進位的主因,在於有更多的分數能夠「漂亮的終結」。例如,十進位制裡,1/3 會變成麻煩的無限小數 0.33333;十二進位裡,1/3 就是 4/12,小數寫成 0.4。十二進位制的擁護者認為,這套制度能減少四捨五入的必要性,解決許多目前十進位制所引起的捨入誤差 (rounding error)。(https://reurl.cc/NZk1eQ)
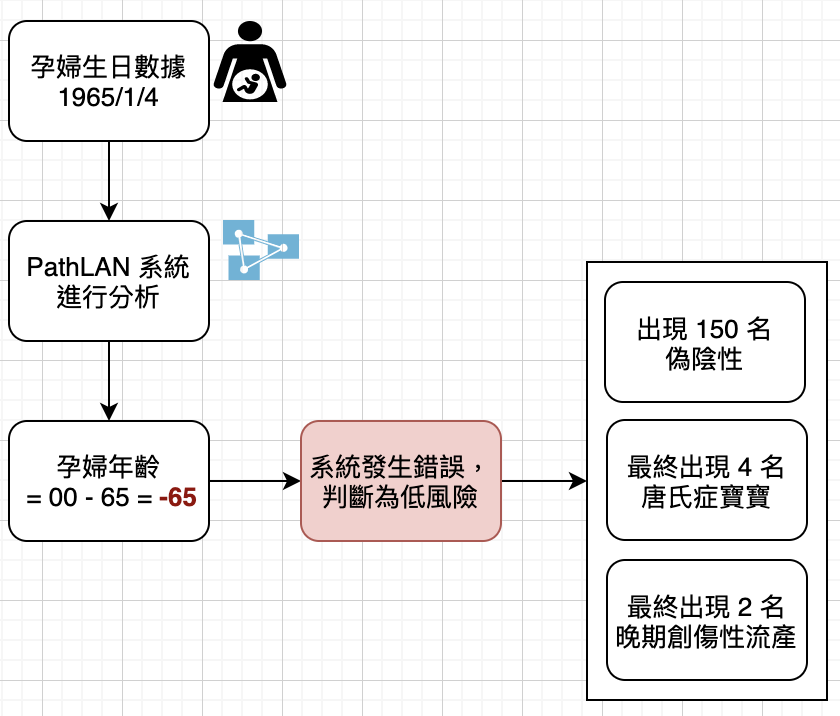
千禧蟲危機 (Year 2000 Problem, Y2K) 是指由於電腦程式設計的一些問題,使得電腦在處理2000年1月1日以後的日期和時間時,可能會出現不正確的操作,從而可能導致一些敏感的工業部門 (比如電力,能源) 和銀行,政府等部門在2000年1月1日零點工作停頓甚至是發生災難性的結果。🏥 位於英國 Northern General Hospital 的唐氏症檢測中心,其 PathLAN 系統就是因為沒修復 Y2K 而導致憾事發生。

二進制 (binary)