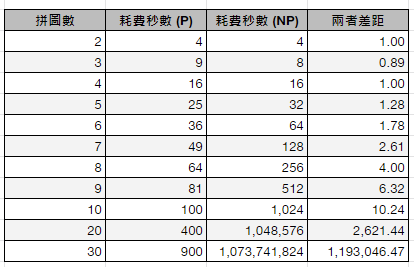
演算法其實是一連串的指示,用來明確完成某一項任務,從整理手邊蒐集的唱片到做出一到菜等。然而,史上最早的演算法,本質上是很單純的數學。
現在電腦執行的演算法日益複雜,當我們想要有效率的處理日常事務時,演算法變成不可或缺的一環。以往的解答已經無法滿足我們的需求
P/NP 問題的核心:針對問題的答案做驗證,通常比找出問題的答案還容易。這個數學未解之謎真正要問的是:如果某個解答能用電腦快速驗證,是否也能用電腦快速求解?

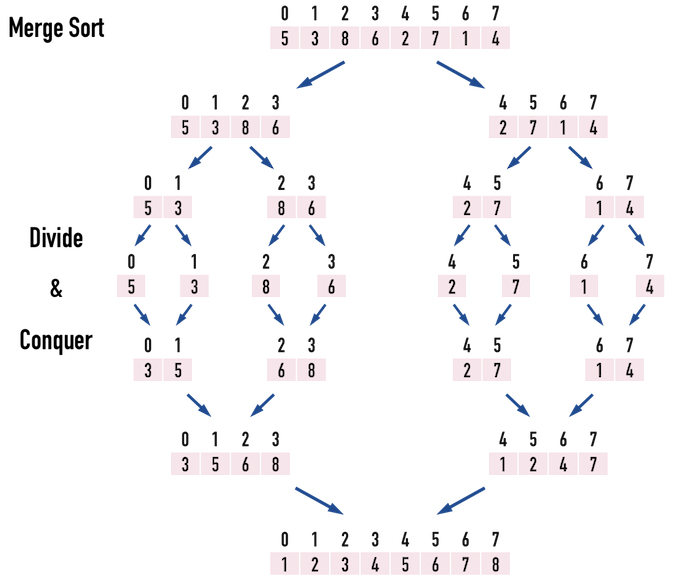
Bubble Sort、Insertion Sort、Merge Sort 《Algorithms to Live By》


排序與運動賽事的類比 《Algorithms to Live By》
旅行推銷員問題 (Travelling salesman problem, TSP),是組合最佳化中的一個NP 困難問題,在作業研究和理論電腦科學中非常重要。問題內容為「給定一系列城市和每對城市之間的距離,求解訪問每一座城市一次並回到起始城市的最短迴路。」旅行推銷員問題有個「決策版本」,它只問有沒有比某長度更短的路徑,就是 NP-Complete 問題的經典範例。理論上,如果能提出一套可行的演算法,解出某個 NP-Complte 問題,就能轉換這套演算法來解決其他 NP 問題,這樣就能證明 P = NP。
P 與 NP 的對抗,其實是在確認人類的創意是否能自動化。若 P = NP,那麼任何可證明的數學定理,電腦都能在一定的程式序列內找出證明。這代表過去人類許多偉大的智力成就 (ex. 牛頓的運動定律、達爾文的自然選擇演化論、愛因斯坦的廣義相對論、懷爾斯的費馬最後定理證明),只需一台機器即可複製並取代,許多數學家將因此失業。
我們有時候不一定想要完美但緩慢的方案,反而寧願接受普通但快速的方案。例如,💼 在上班前,我不太需要研究怎麼擺才能讓公事包裡的物品占據最小空間,只要能讓所有東西塞進去即可。啟發式演算法 (heuristic algorithm,又稱經驗法則),就是讓我們在面對許多不同問題時,得到與最佳解相去不遠的解決方案。
貪婪演算法 (greedy algorithm) ,是一種短視的演算法,靠著找出當下問題的解決方法,希望最後找出整體問題的最佳解。貪婪演算法,一定能找出某種解決方案,卻無法保證最後得到的是最佳解,有時候甚至稱不上普通解。但確實有些問題,能夠用此法得到最佳解。
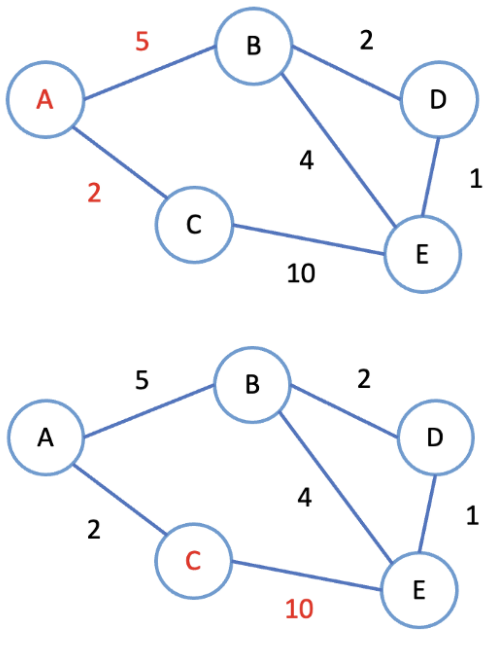
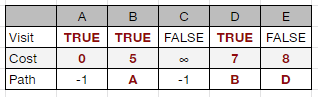
汽車衛星導航採用 Dijkstra's algorithm (戴克斯特拉演算法),是一種 greedy 演算法,每次都去找當前最小的那一條路,能在多項式時間 (polynomial time) 內快速找出「最短路徑」的答案。



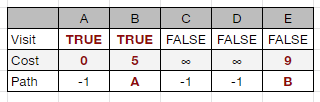
群體智慧 (Swarm Intelligence) 是自然科學研究的領域,他研究的對象主要是自然群體生物在現實環境中,各種群體行為的相關議題,例如:路徑規劃、任務分配和築巢…等。很多時候甚至可以觀察到,即使是弱小的生物個體,當群聚一起時,卻可以展現出極其複雜的集體行為。常被研究的自然群體生物有:細菌菌落、魚群、螞蟻群、蜜蜂群、蝗蟲、鳥群、靈長類部落,當然其中也包含了人類。研究這些群體是非常有趣的,例如:螞蟻群在工作時,儘管沒有領袖發號司令,卻可以在移動過程中漸漸地找出最佳移動路徑。演算法設計人員從動物間的互動得到靈感,可以派出大量彼此連結緊密的人工智慧體 (artificial agent),讓它們去探索某個環境;這些人工智慧體能夠如動物群體般的迅速溝通互動,在搜尋環境的過程中,互相掌握其他個體的發現。它的控制是分布式的,不存在中心控制。(https://reurl.cc/73ORrN)
在我們眼中,有許多物種適應良好,堪稱典範。但有可能演化還沒找到最佳方案,只是我們想像力不足,才會誤會這已是「完美」的方案;幸好有隨機的組合與突變,能讓我們擺脫局部最大值,進一步找到更好的解決方案。

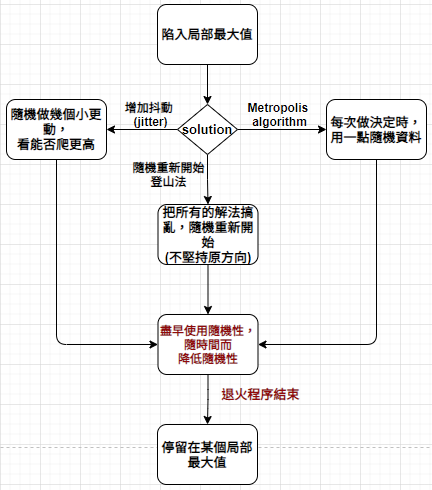
隨機性演算法未必能提出最佳解,但它不用像確定性演算法那麼辛苦,只要有計畫地丟幾個硬幣,就能在短短時間內提出相當接近最佳解的答案。隨機性演算法用於特定問題的效果,甚至超越最好的確定性演算法。問題的最佳解決方法有時候是交給機率決定,而不是自己試圖推出答案。運用隨機法,想辦法從局部最大值,變成整體最大值。《Algorithms to Live By》
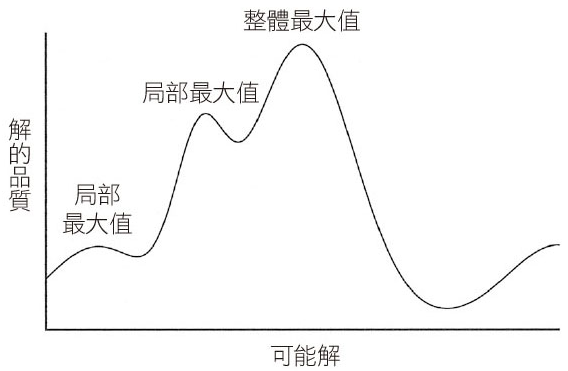
無論是抖動、隨機重新開始、或是接受解決方案偶而變糟,隨機性用於避免局部最大值的效果都很好。機率不只是處理困難最佳化問題的可行方法,在許多狀況下還是必要方法。從模擬退火法可以得知,你應盡早使用隨機性,並快速離開隨機的狀態,隨時間而降低隨機性,停留在接近結冰的時間最久。壓住火氣,不要急躁。《Algorithms to Live By》
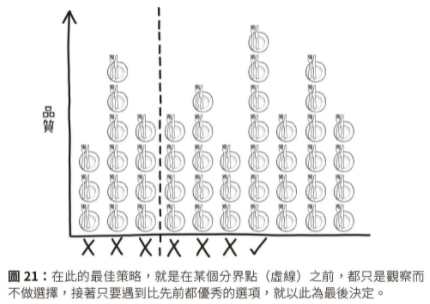
在最佳停止問題 (Optimal Stopping) 中,真正讓人困擾的不是該選擇哪個,而是可以考慮的選項有多少。面臨這類問題的不只有情侶與想租房子的人,還有駕駛人、想買屋的人、竊賊、開車度假找旅館的人等。37% Rule 源自於著名的最佳停止問題 - 秘書問題 (secretary problem):《Algorithms to Live By》

世上有很多人都會跟我們處得不錯,能讓我們有幸福的一生。最佳停止時機的策略,並不會提供所有人生問題的答案。我們雖然可以用演算法來簡化、加速單調乏味的任務,但風險也伴隨而來。因為演算法包含輸入、規則和輸出,也就代表有三個可能錯誤的地方。就算使用者確信所用的規則完全符合需求,只要輸入有誤或輸出不符合規範,就可能導致災難。
💠🤖 現在的股市交易,已有越來越多是程式交易 (algo trading),因為面對市場的種種變化,電腦察覺並做出回應的速度遠快於真人。根據估計,Wall Street 的交易已大約有 70% 都是由這種所謂的黑盒子機器來處理。
📉 2010/5/6 美股遭到閃電崩盤 (flash crash),電腦股票系統被不明原因觸發,連編寫程式的人也不了解電腦做的交易。道瓊工業指數在 5 分鐘內下跌近 600 點,電腦間在 15 秒內互相交易 27,000 份期貨合約,最終因期貨市場內建的保護機制,將所有交易中止 5 秒鐘,電腦的瘋狂交易就令人讓人難以置信的恢復正常。電腦的演算法是人撰寫的,電腦沒有常識,只會盲目地買進與賣出,因為這就是它的演算法要求它們做的事情。《Standard Deviations: Flawed Assumptions, Tortured Data, and Other Ways to Lie with Statistics》

Navinder Sarao 在自家臥室就成功操控了股市,正說明用演算法發動惡意攻擊是多麼容易的事。我們太常把演算法視為一系列公正、不帶偏見、不受情緒影響的指令,而忘了所有演算法背後都隱藏著一開始研發的目的。
即使演算法事前定義,在執行時也公正不阿,但即使設計者確實抱持公正的初衷,也不代表當初設計的目的完全不帶偏見。規則是人訂的,無論有心或無意,程式設計師都可能把自己的偏見帶進演算法本身,寫成程式後,令人一時看不出那就是先入為主的偏見。
華盛頓郵報引述的內部文件揭露,臉書的排名演算法自 2017 年開始,將「怒」等表情符號回應的價值視為比「讚」高出 5 倍。背後理論很簡單,激起很多情緒符號的貼文往往會確保用戶提高參與,而確保用戶參與率對臉書有極大好處。報導更指出,演算法推廣的力量則破壞了內容審查員及操守團隊對抗有毒及有害內容的努力。臉書前產品經理兼「揭弊者」Frances Haugen 告訴英國議會,「憤怒與仇恨是臉書上最簡單的增長方式」。(https://reurl.cc/mvabnA)
隨著演算法日益複雜,輸出結果也越來越難以預測,所以需要加強控制與人為監督。然而這些控制與人為監督,絕不只是科技龍頭企業的責任。身為這些科技龍頭企業的 end user,也須負起部分責任,判斷自己得到的 output 真實無偽,例如:❶ 📰 對於自己讀到的新聞,是否要相信此消息來源?❷ 🛰️ 對於汽車導航的建議路線,是否要照著走?